Overview
Language type
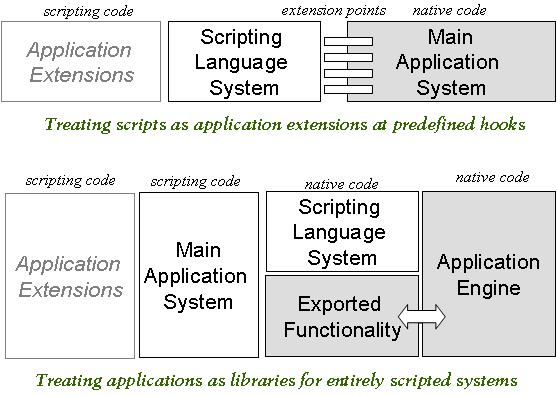
The Delta language is untyped object-based (classless), dynamically-typed (weakly, duck typing), lexically-scoped, garbage collected, compiled to platform-neutral byte code, run by a virtual machine . In this sense, it has similarities to Lua and JavaScript, but not to Python and Ruby - the last two, although dynamic, are class-based and typed. A Delta source program (.dsc files - DeltaSource Code) is compiled to platform-neutral byte code (.dbc files - Delta Byte Code) which can be loaded and run by a virtual machine. Every loaded program has its own separate virtual machine with its own runtime stack. Virtual machines are first-class values carrying loaded programs being essentially first-class packages. A source program in Delta is a sequence of statements mixed with function definitions. When a program is run, all such statements (not the function definitions) are sequentially executed.Delta programs may run standalone or may be embedded in C++ applications. In the former case, a Delta program may load and use application-specific libraries as dynamic libraries (DLLs), implying gluing or application logic code is written in Delta. This development model is increasingly becoming popular for scripting languages. In the latter case, application developers decide explicit extension points in their code by implementing hooks to invoke Delta code. This model treats Delta as a tool to allow post-production application extensions, and it was a popular model for exploiting scripting languages in the past (currently it is fading out).
The two models, both supported by Delta, are outlined below. We believe that the second model will dominate: high-performance, application-specific libraries (we can call that an application engine) will be programmed in the native language, while the entire logic for an actual application will be programmed in the scripting language.
|
|
|
***Application scripting models (both supported by Delta)*** |
Language implementation
The Delta language has a full-fledged multi-platform implementation in C++, with the current source-code base being approximately 330 KLOCs (excluding third party libraries). The language and its tools are all implemented from scratch, meaning they do not rely on third-party language tools or technologies (like DLR, Eclipse or Visual Studio). Overall, our implementation includes: compiler, virtual machine, debugger backend and frontend, standard runtime library, extra libraries (AOP, CORBA, JSON, wxWidgets, XML), and an IDE with self-extensibility, syntax highlighting and two source-level debuggers.The language system offers a powerful embedding library (for interoperation with C++) and a feature we call just-in-time tracing collection that disposes objects immediately after they become useless. Additionally, it supports collection for native objects (users may provide to Delta any C++ object, including containers of Delta values, that can be collected by the Delta garbage collection system).
Our work in the Delta language combines research on: language design, language implementation, and integrated development environments.
We strongly believe that the combined focus on all these research areas leads to more rapid progress and more useful results in each individual area.
We are constantly working on the interplay of languages and tools, where both are (re)designed and (re)implemented to empower each other for the benefit of their users. In particular, our work in the Delta language and the Sparrow IDE reflects our focus on the following research topics:
Dynamic untyped object-based languages for full-power untyped OO programming (classes, overloading, inheritance, polymorphism, genericity).
Debugger friendly virtual machines (runtime collection of metadata which cannot be statically computed).
Next generation debugger backends (language-agnostic object inspection, object graphs with referrers and referrents information, object slot classification properties).
IDEs supporting whitebox add-ons (users can define, manage, control, inspect and refine add-ons).
IDEs supporting fast and easy circular debugging of add-ons (allow to debug addons within the entire running IDE using the IDE itself).
Language style
Below there are a few code samples that are indicative of the Delta language style. As in many languages, variables are implicitly declared by use, while they are dynamically typed (they take at runtime the type of the value they are assigned). Also, variables are lexically scoped.x = 10; // 'x' declared, assigned 10, type becomes 'Number' { // opening a block (entering scope) x = "hello"; // previous (global) 'x, now assigned 'hello', type set as 'String' print(typeof(x)); // prints type of global 'x', being 'String' local x = ::x +",world"; // new local 'x' at block scope assigned the global 'x' + ',world' print(typeof(x)); // prints type of local 'x' (closest one), being 'String' print(typeof(::x)); // prints type of global 'x', also being 'String' print(x, "\n"); // prints value of local 'x' and a new line print(typeof(print)); // prints type of library func 'print' being 'LibraryFunc' } // closing the block (exiting scope)Function definitions are syntactically like statements. To use a function definition directly as an expression it has to be surrounded by parenthesis. Anonymous functions are supported by simply skipping the function name. When a function has no arguments you may optionally skip the '()' part denoting empty arguments.
function f (x,y) // definition of a named function 'f' at global scope { return x + y; } // no trailing ';' is needed after func (harmless to add one) print(typeof(f)); // prints type of 'f' being 'ProgramFunc' string const nl = "\n"; // defines a constant 'nl' at global scope print((x = f)("1", 2), nl); // assigns 'f' to 'x', calls 'f' with '1' and 2, printing '12' f = x; // compile error, as user-defined functions are not variables id = // 'id' is a var asigned a func expression ( function(x){ return x; } ); // any func definition around ( ) is an expression print(id(id)); // calls 'id' on itself, printing the anonymous function valueObjects are created ex nihilo by object construction expressions of the form [ <slot definitions> ] and are garbage collected. Slot definitions concern explicitly or automatically indexed slots (the latter take successive numeric indices, following their order of appearence, starting from 0). For indices any value may be used, not just numbers or strings, except nil that can be used neither as a slot index nor as a slot value. In fact, setting a slot with nil causes removal, while testing the existence of a slot is possible by comparing its value with nil (since it can't be a slot value).
a = []; // ex nihilo creation of an empty object a = ["one", 2, function three{}]; // make an object with three elements indexed as [0] [1] [2] print(a[0], a[1], a[2]); // prints 'one', 2 and the value of the 'three' function three(); // notice that 'three' is a visible function at this point a.three(); // runtime error, functions are not indexed by name a.three = three; // should add explicitly a slot with a desriable index a = [ @three : function {} ]; // this is the way to do it in object constructors a = [ { "x", "y" : 10, 20 } ]; // make an object with slots 'x' : 10 and 'y' : 20 a.x = a.y = "goodbye, world"; // write 'x' and 'y' slots with the same 'String' value print(typeof(a), typeof([])); // prints 'Object' twice, as the type of all objects is 'Object' a = [ method move (dx, dy) { // methods are allowed only inside object expressions self.x += dx; // 'self' is a keyword referring to the method owner object self.y += dy; // slots are late bound, requested upon method invocation }, { "$1" : method{} } // alternative syntax if the method name is not an identifier ]; a.x = a.y = 30; // here we actually set the 'x' and 'y' slots of 'a' a.move(-10, -10); // and we invoke a method by its name a."move"(-10, -10); // this syntax is also possible a."$1"(); // it is usefull to access methods with non-identifier names a["$1"](); // this is the traditional style and applies too print(a.x == nil); // will print 'false' a.x = nil; // will remove 'x' slot print(a.x == nil); // now will print 'true' print(a[nil]); // runtime error: nil is forbidden as a keyTypical control flow statements are supported like if-else, while, for and an extensible foreach enabling iteration on user-defined containers. The syntax resembles that of C.
if (foo) print("true"); else print("false"); while (bar) { print("still true"); if (foo) break; else continue; } for (local i = 0; i < N; ++i) (function{})(); // invoke an anonymous function foreach (x, [0, 1, 2, 3, 4]) // iteration order in objects is undefined print(x); foreach (f, [function{}, function{}]) // the object slots are two anonymous functions f();
Standard features
Below we provide a list of features which are standard in the Delta language. Such features are typically met in advanced dynamic, class-based or classless, languages. For the detailed description you may refer to the programming guide document.Untyped objects with ex nihilo construction
Object instances are produced at runtime every time an object constructor expression is evaluated. Such expressions have the syntax [ <slot definitions> ] , while with every evaluation a new distinct instance is produced. Examples are provided below:
a = [ 1, 3, 5 ]; // an object with slots <0:1, 1:3, 2:5> (first is auto key) print(a[0], a[1], a[2]); // syntax to access slots of any key type is <obj>[<key>] b = [ { #x, #y : 0 } ]; // an object <x:0, y:0> with #<id> being equivalent to "<id>" b = [ @x : 0, @y : 0 ]; // alternative syntax with @<id> : expr same as { "<id>" : expr } b.x = 20; // accessing slots of identifier keys (syntactic sugar to b["x"]) c = [ method f{} ]; // an object <f: method{}> c = [ @self ]; // '@self' (kwd) refers to the object under creation print(c == c[0]); // will print 'true'First-class anonymous methods
Method definitions are allowed only as slot definitions of object constructor expressions, while they are always anonymous . Methods can be stored in slots of any key value, besides string-identifier keys; however, for identifier keys syntactic sugar is provided to make method definitions more clear. The reason methods are anonymous is because they always 'reside' within object slots visible with their respective indices (keys). Thus, since it is always possible to refer to method slots, there is no need to statically 'lock' the name of a method.
The latter allows change the way a method is referred (its slot key) dynamically, or even use multiple such keys. Additionally, as explained under the section on ' novel features', we allow methods to be added and invoked on any object, a sort of fine-grained reuse downto individual methods, like traits . Examples on methods are provided below:
a = [ @f : method {}, // new object on var 'a' with a method in slot 'f' @g : method {} ]; // and another method in slot 'g' a.f(); // invoking a method for an identifier key a."f"(); // this is also valid and works for any string key f(); // compile error (not a callable), as methods invisible outside b = [ method f{} ]; // this is syntactic sugar for method slots with id keys b.f(); // syntactic sugar of field access applies as before c = [ { "$1" : method{} } ]; // methods may be stored to slots of non-id string keys d = [ { -1 : method{} } ]; // methods may be stored to slots of any key c["$1"](); // the generic syntax for slot access can be used c."$1"(); // this form can be used too d[-1](); // for non-string keys the [] syntax is used fm = a.f; // 'fm' is a method value, copying 'a.f' fm(); // can be called directly not requiring an object fm = c."$1"; // as before we get the method value fm(); // and we invoke it without the object print(fm.self); // will print object 'c' ('self' key allowed only on methods) print(fm.self == c); // will print 'true' print(fm.self.self); // will print 'nil' (for objects 'self' is a user-defined slot) fm.self.self = "foo"; // sets 'self' slot of 'fm' owner to 'foo' print(fm.self.self); // this will print 'foo'Self-object visibility inside methods
In Delta, self (keyword) is an automatic internal parameter (no need to explicitly declare it), and refers to the object receiving the method invocation request. It applies only inside methods.
a = [ // 'a' is a new object method add(d) // it has a method named 'add' { self.val += d; } // in methods we use 'self' to access slots ]; a.val = 10; // we can introduce slots on objects dynamically a.add(20); // here when 'a.add' is invoked 'self' is 'a'First-class functions
Function names are r-values (immutable) that can be normally used in expressions, stored in object slots and passed to- or returned by- functions (higher-order functions). Examples are provided below:
function foo // a function with no parameters - may skip '()' { print("foo"); } function bar (f) { f(); return f; } // a function invoking and returning its argument bar(foo); // will print 'foo' function h(f, g, x) // a function with function (callable) arguments { return g(f(x)); } h(bar, bar, foo); // will print 'foo' twice bar(bar(foo))(); // will print 'foo' three times a = [ foo, bar ]; // make an object with two function slots a[1](a[1](a[0]))(); // this is equivalent to 'bar(bar(foo))()'Function definitions as expressions
A function definition can be used as an expression when surrounded by parenthesis, that is (<function def>) is a function value. Such values can be involved in expressions as with function names. A function defined this way is visible inside the entire block where the expression appears. The parenthesis are optional when the function definition appears as an argument to a call, or as a value in a slot defintion . Examples are provided below:
(function foo { print("foo"); })(); // 'foo' defined and invoked directly here print( function bar (f) // 'bar' defined and supplied as an argument { f(); return f; } ); [ { 0 : function{} } ]; // anonymous function as an explicitly indexed slot [ function g{} ]; // named function as an automatically indexed slot foo(); bar(foo); g(); // all named functions are visible at this pointAnonymous and lambda functions
Anonymous and lambda functions are supported, which when combined with the previous feature move closer to a functional programming style. Examples are provided below:
l = std::list_new( // make a list with a few initial elements 10, // list elements may be of any type "hello", "world", function(l) // an anonymous function element { print(l); } ); foreach(x, l) (function(x) { // define an anonymous function if (typeof(x) == "ProgramFunc") // test the type of a value dynamically x(l); // we invoke funcs passing 'l' as arg })(); // invoke the anonymous func per element (function(f){ f(); })( // anonymous func invoked directly function{} // anonymous func supplied as argument ); (f = (function{}))(); // anonymous func assigned to 'f', then invokedLambda functions are syntactic sugar for anonymous functions that return a single expression (clearly, not a lot of typing is saved). Usually they are preferred due to stylistic reasons by being closer to the functional look-and-feel. Here are a few examples:
(function (cont, pred, action) { // an anonymous function with three args foreach (local x, cont) // iterate to elements 'x' of container 'cont' if (pred(x)) // if the predicate 'pred' is satisfied on 'x' action(x); // then invoke 'action' on 'x' })( // we invoke directly the anonymous function l, // the previously defined list 'l' lambda(x) // a lambda function with a single arg { typeof(x)=="Number" and x%2==0 }, // the predicate is satisfied for even numbers lambda(x) // a lambda function with a single arg { print(x) } // it prints its arg ); // it will print '10'Anonymous reference to enclosing function or method
As explained earlier, besides anonymous and lambda functions, in Delta all methods are anonymous. In such cases, if recursive invocation is needed, or when the value of the function / method must be used in an expression, we need a way to allow refer to the current anonymous function / method. This is possible through the @lambda keyword, which is a general 'synonym' for the current function / method (in fact, it can be used even within explicitly named functions). Examples are provided below:
fib = (function(n) { // as an anonymous function if (n == 0) return 0; else if (n == 1) return 1; else return @lambda(n-1) + @lambda(n-2); }); // enclosing parantheses necessaryIn the previous code 'fib' is a variable, so, although its tempting to add fib(n-1)+fib(n-2) in place of the previous code, the function will then depend on the value of global variable 'fib', an apparent malpractice. An alternative version using lambda functions follows. Notice that in Delta the syntax of the ternary operator is ( expr ? expr : expr ) meaning the extra surrounding pair of parenthesis is mandatory (a little more verbose than C).
fib = lambda(n) // as a lambda function { ( n < 2 ? n : @lambda(n-1) + @lambda(n-2) ) };Nested functions with closures
Nested functions are supported that normally provide access to global variables, and all functions visible at the point of their definition. Additionally, via closures, access is granted to local variables and formal arguments of the outer, i.e. directly enclosing, function and to local variables of any outer block of the main program only if the current function is a top-level function. The latter constitute the closure for an inner function, and are called closure vars, and upvalues of its closure. Additionally, in the Delta language access is provided to all closure vars of the outer function (thus an inner function has access to closure of its outer function).
Although closures are supported in the Delta language, all their goodies can be effectively emulated through functors which essentially prescribe functions with state. The choice depends on your preference in using either a function object with a whitebox state where all facilities of the object system directly apply (functor) or a function with a blackbox state (closure). For more information on functors you you may refer to the operator overloading document for more details. Simple examples showing use of nested functions and closures are provided below.
function f { const N = 10; // a constant local to 'f' function f(x,y) { function g { local v = N; // non-local constants are visible const N = 20; // but can be redefined (shadowed) return f(x, y); // 'x' and 'y' visible, closure vars for 'g' return f(0,0); // outer 'f' is visible local x; // this is local 'x' declaration } local x; // this will shadow the 'x' arg function { x = 20; } // 'x' visible, closure var for anonymous func function { ::f(); } // global 'f' function visible } } y; // implicit declaration of global 'y' { // a block at global space local x; // 'x' is a local var (block scope) function { x = 20; // 'x' visible, clsoure var for anonymous func y = 20; // but can access directly global 'y' } } function bind1st(f, x) // A simple binder using closures. { return lambda { f(x, ¦arguments¦) }; }
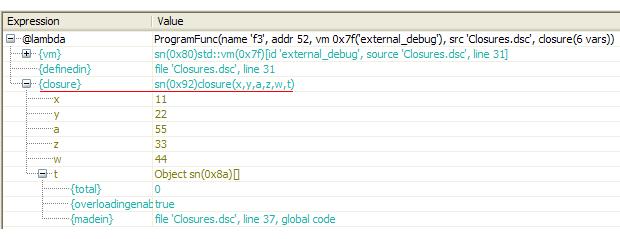
It should be noted that, debugging-wise, closures are always whitebox in the Delta language due to the powerful debugger inspection features which allow view closure contents (see figure below).
|
|
|
***The closure shown during debug inspection*** |
Keywords and operators
Keywords
if else while for foreach
break continue function method using
try trap throw static local
const lambda @lambda @set @get
self @self @operator return assert
onevent arguments nil and not
or true false
Operators
Arithmetic
+ - * / %
Pre / post increment / decrement
++ --
Ternary
( ? : )
Relational
!= == > < >= <=
Logical
and not or
Function call / expression grouping
()
Slot access
[] [[]] . ..
Assignments
= += -= /= *= %=
For operator overloading
+_ -_ *_ /_ %_
==_ !=_ <_ >_ <=_ >=_
.= =()
Special
:: # ... @
Metaprogramming
<< >> ~ ! & $
Punctuation
{ } ; , :
Novel features
Integrated metaprogramming
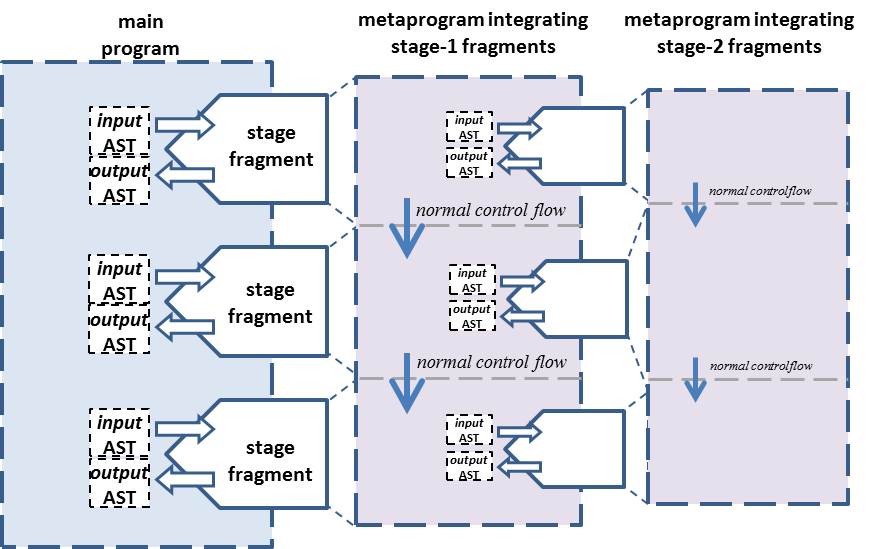
Delta introduces a metaprogramming model that treats distinct meta-code fragments as a single coherent metaprogram. In this sense, the typical unrelated and localized transformations now become collective transformations of a target program source: the final program can be transformed / generated by an integrated metaprogram executed during compilation, while the source of that metaprogram may in turn be transformed / generated by a nested integrated metaprogram. The target is for the metaprograms to be engineered and developed as normal programs reusing all normal language features, tools and coding practices.An integrated metaprogram is the program resulting by assembling together all code fragments of the same stage nesting, following their actual order of appearance in the main source. Such fragments retain their original link to the main source in terms of the input they receive, and the output the produce. In this sense, separate metaprograms in a traditional model, spread across different parts of a main source, are now treated as source fragments of the same integral metaprogram.
Their evaluation of an integrated metaprogram is essentially the sequential execution of its source fragments. This means, that integrated metaprograms can share state, and may be implemented following the typical global control flow of programs, despite the fact they may be syntactically scattered
Below we illustrate the integrated metaprogramming model, depicting source transformations, stage assembly, evaluation order and lexically-scoped (sequential) control flow.
|
|
|
***Concept of an integrated metaprogram comprising all staged code fragments at the same nesting with their order of appearance and denoting a lexically-scoped control flow.*** |
More information is provided on the discussion on metaprogramming, while integrated metaprogram examples can be found here.
Methods with a mutable self
In Delta, methods are fully supported as first-class values, enabling access or mutate the owner object (self). Internally, method values are atomic pairs of a code address and an object reference (self). Every time an object constructor expression is evaluated and a new object instance is produced, all method definitions from this expression introduce method-value slots to the newly created object. Each such method-value slot is given as object reference (self) the new object. When a method is invoked, the owner object is always passed as an implicit parameter named self, visible inside the method body.Because method values already carry the value of self, they can be called without syntactically requiring to denote the calee object. The latter is a feature also supported by Python. The examples below demonstrate the invocation of method values without requiring an object and the feature of owner mutation.
a = [ // 'a' takes a reference to a new object method foo // the new object has a 'foo' method { print(self.val); } // the method prints the self 'val' slot ]; m1 = a.foo; // 'm1' is a method value copying 'foo' value print(m1.self); // 'm1' self slot can be freely taken print(m1.self == a); // will print 'true' m1.self.val = 23; // we can access all slots of the self object normally m1(); // we invoke 'm1' directly, this will print '23' a = [ @val : "twenty three" ]; // we set 'a' as another new object m2 = m1; // 'm2' is a copy of the 'm1' method value m1.self = a; // we mutate the owner of 'm1' method to be the new 'a' m1(); // this will now print 'twenty three' m2(); // but this prints '23' as 'm2' has the previous onwer m2.self = m1.self; // however, we can change 'm2' owner to be that of 'm1' m2(); // thus now 'm2' prints 'twenty three' as well a.bar = tabmethodonme( // this library function accepts an object ('a' here) a, // and a method (slot [0] of new object here) and [ method(v) { @val = v; } ][0] // returns a copy of the method value with owner ); // the supplied object (thus 'a') a.bar(23); // invokes the new method with self being 'a' a.foo = tabmethodonme(a, m1); // add 'm1' method in new 'a' object with 'foo' key a.foo(); // will print '23' as 'val' slot changed by the method
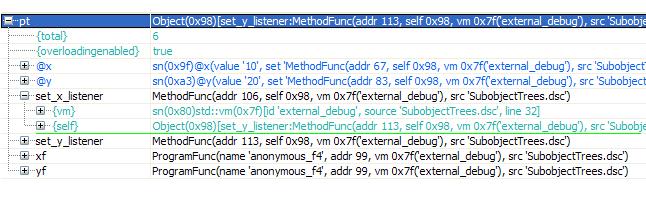
A mutable owner allows programmers to create new objects by combinig selectively methods from other objects. This allows fine-grained reuse of methods without requiring build or rely on inheritance schemes, something that may allow better separation of concerns for some reuse scenarios. Additionally, the ability to invoke methods directly as functions, without syntactically requiring an object, enables methods play the role of functors, i.e. functions with their onwn copied state visible via self slot. As shown below, the owner object of a method (i.e. self slot), is also displayed when inspecting method values.
|
|
|
***The owner object ('self' slot) of methods is shown during debug inspection*** |
More information is provided in the discussion on methods.
Orphan methods
As mentioned earlier, in the Delta language all methods carry internally their self object, which is also syntactically accessible via .self and binds to the object in which it is initially hosted. Thus, to get a method, one has to always define an object construction expression encompassing the desired method, and then get the method through the object. But there are many situtations where methods are simply defined to be applied to various objects with differing slots (one could say those objects are of a different designed class). In this case, the object constructor is just syntactic overhead. For this purpose, orphan methods are supported as shown by the examples below. Notice that orphan operator methods are not supported. Syntactically, orphan methods are treated just like functions.method m {} // Orphan method definition - this 'm' is a variable. m = [ method {}][0]; // Actually, the previous is syntactic sugar for this. m = nil; // Orphan methods define vars when their name is seen first time. function f {} // Function definition, this 'f' is immutable. f = nil; // Thus this would cause a compile-time error. method f {} // This is an error too, as we try to assign a method to immutable 'f' m = (method {}); // The parentheses are needed here to make method definitions be expressions. method print_xy { print(@x, @y); } // This method prints the 'x' and 'y' local slots / attributes. print_xy(); // The initial object has no 'x' or 'y' thus prints NilNil print_xy.self.x = 10; // Here we can even use the internal object of an orphan method. print_xy.self.y = 20; // And set its slots, as we do here. print_xy(); // This will now print 1020 print(print_xy.self[0]); // Notice that an orphan method is stored in the [0] slot of its initial self. print_xy.self = [ @x : 9, @y : 7 ]; // Here we change the 'self' object (owner) of 'print_xy' method print_xy(); // Hence, this call will now print '97' print(print_xy.self[0]); // This will print 'Nil' since the new self has no [0] slot.More information is provided in the discussion on methods.
Binary-operator overloading
Although Delta is a classless language, it offers a facility for (untyped) overloading of binary operators by objects with expressive power similar to typed overloading. The basic arithmetic and relational operators can be overloaded, as well as the assignment and the conversion operator:Arithmetic: + - * / %
Relational: > < >= <= == !=
Assignment: =
Conversion: =()
The examples below demonstrate how untyped object-based operator overloading is supported. As shown, operator functions are first-class values, indexed using their operator lexeme.
function Point (x, y) { // an example of a 'Point' factory function return [ // creates and returns new object everytime @class : #Point, // user defined 'class' slot; #<id> same as "<id>" { #x, #y : x, y }, // assignment to object slots from the arguments method @operator+(l, r) { // both arguments supplied to binary operator functions assert r.class == #Point; // a trivial form of user-defined type checking return Point( // we return a new temp Point object @x + r.x, // @<id> is same as self.<id> @y + r.y ); } ]; } pt1 = Point(1,2); // make a sample 'Point' instance pt2 = pt1 + Point(-1,-2); // 'pt2' is the result of adding 'pt1' with a temp 'Point' print(pt1.+); // could also write pt1["+"]; prints the operator method pt2[+] = nil; // we remove the operator method (unoverloading) from 'pt2' pt3 = pt2 + pt1; // fails at runtime since 'pt2' does not overload '+' pt2.+ = Point(0,0).+; // we reoverload 'pt2' taking the operator from temp 'Point' pt2.+.self = pt2; // and then we set the operator method's owner to be 'pt2' pt3 = pt2 + pt1; // now the operator invocation will succeed tabdisableoverloading(pt2); // we can disable overloading on 'pt2' pt2 + pt1; // runtime error, overloading disabled for 'pt2' pt1.+_ = pt1.+; // we allow 'pt1' overload '+' even when at RHS pt2 + pt1; // here pt1.+_(pt2, pt1) is called, thus handled by 'pt1' tabenableoverloading(pt2); // we enable overloading on 'pt2' pt2 + pt1; // now pt2.+(pt2, pt1) is called, thus handled by 'pt2'As shown below, because overloaded operators in Delta are treated as first-class object slots, they are displayed when inspecting objects through the debugger as all other slots.
|
|
|
***The operator slots of objects are shown during debug inspection*** |
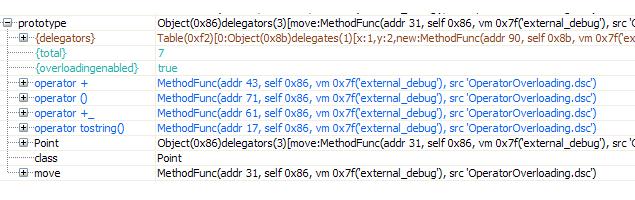
More information on the overloading of binary operators as well as all the rest of operators is provided in the discussion on operator overloading.
Dot overloading
Dot overloading is the ability to supply a user-defined method for slot access. The latter concerns both the reading and writing of object slots, handled via two separate operators: dot and dot-assign . These operators are overloaded dynamically on objects by simply setting two reserved slots for the keys: '.' for the dot operator, and '.=' for the dot-assign operator. The built-in operators are still available via the library functions tabget(<obj>, <key>) and tabset(<obj>, <key>, <value>) . The example below illustrates the various ways in which dot overloading is supported.function dot(obj, key) // a trivial user-defined dot calling the built-in version { return tabget(obj, key); } // 'dot' is not a reserved name, we could name it 'foo' function dot_assign(obj, key, val) // a trivial user-defined dot-assign calling the built-in version { tabset(obj, key, val); } // 'dot_assign' is not a reserved name, we could name it 'bar' a = []; // just making an empty object for our example a[.] = dot, a[.=] = dot_assign; // we just overloaded the dot and dot-assign methods print(a[.], a[.=]); // they are normal slots, so can be extracted and printed a.x = 10, a.y = 20; // these are now handled by the our 'dot' and 'dot_assign' functions a[.=] = nil; // by removing either or both slots we return to the built-in versionDot overloading is useful for implementing user-defined objects models, including custom object-based inheritance frameworks, but also for creating very intuitive proxies. Below we demonstrate the implementation of a proxy factory which delegates all slot access to its associated object:
function Proxy (a) { return [ @server : a, // we store the server in a slot method @operator.(obj, key) // dot overloading syntax using operator methods { return tabget(obj, #server)[key]; }, // we use built-in dot to get 'server' object slot method @operator.=(obj, key, val) // here we similarly overload dot-assign { tabget(obj, #server)[key] = val; } // and again redirect dot-assign to the 'server' ]; } a = Proxy([]); // make a proxy for an empty server object a.x = a.y = 20; // these slots are set on the server object print(tabget(a, #server)); // we may still get the server via the built-in dot a = Proxy(a); // and we can even make a proxy for a proxy objectAs shown below, because dot operators in Delta are treated as first-class object slots (as all the rest of overloaded operators), they are displayed when inspecting objects using the debugger as any other slot.
|
|
|
***The dot and dot-assign operator slots shown during a debug session*** |
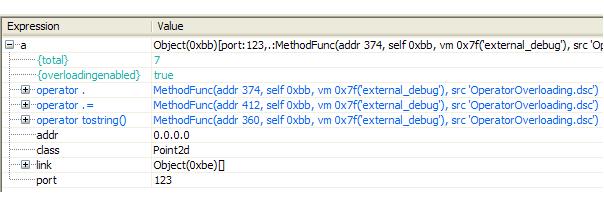
More information on dot overloading as well as all the rest of operators is provided in the discussion on operator overloading.
Function-call overloading
Function-call overloading allows objects be called syntactically as functions, thus be callables, commonly referred as functors . Functors are conceptually functions with their local copied state or memory. Since in our case functors are objects, such local state is syntactically visible through self . Overloading of the function-call operator is done by simply setting the reserved slot for the key '()' with a callable value (function, method or another functor). As with all other overloaded operators, it is a first-class slot that can be read, written or erased. Functors allow to implement higher-order functions easily. Below we provide a few simple examples regarding functors.function const_func (c) { // produces functor f(x) = 'c' (i.e., constant function) return [ // make a new object everytime @val : c, // store the constant 'c' as a slot of the functor object method @operator() // a method overloading the function-call operator { return @val; } // returns the slot storing constant value ]; } c_hw = const_func("hello, wolrd"); // make 'c_hw' equivalent to f(x) = 'hello, world' print(c_hw()); // will print 'hello, world' c_23 = const_func(23); // make 'c_23' equivalent to f(x) = 23 print(c_23()); // prints '23' c_const = const_func(const_func); // make 'c_const' equivalent to f(x) = 'const_func' c_nil = c_const()(nil); // here 'c_const()' is equivalent to 'const_func' print(c_nil.()); // prints the function-call slot of 'c_nil' c_23.() = nil; // removes the function-call slot of 'c_23' print(c_23()); // fails at runtime since 'c_23' no more a callableOne interesting use of functors in the Delta language is for easily implementing binder generators , or simply binders. Take a look at the code fragment below:
function bind_1st(f,x) { // produces g(y) as f(x,y) return [ // we return a functor object actually { #f, #x: f, x }, // store locally 'f' and 'x' method @operator() // binders are functors { return @f(@x,...); } // '...' passes all actual args of current func ]; } p_hw = bind_1st(print, "hello, world"); // a binder for the std::print p_hw("n"); // will print 'hello, world' with a new lineThe previous binder allows bind only the first argument. We can further generalize to make a binder for the first N arguments as follows:
function bind_n (f...) { // '...' as a suffix of formals implies var args arguments.pop_front(); // skip the 'f' argument being the first one return [ { #f, #args: f, arguments }, // we store the bound 'arguments' locally method @operator() { return @f(¦@args¦,...); } // pass stored 'args' and all actual args ]; } p_hw = bind_n( print, "hello", ", world" // here we bind two arguments with a signle call ); p_hw(); // prints 'hello, world'In the previous code, the use of arguments and of the expression ¦@args¦ deserves explanation. In Delta, arguments is a keyword, being an automatically created vector carrying all arguments to a function / method invocation as arguments[0], arguments[1],..., arguments[N-1] with N being the total number of arguments. This vector is not actually used by Delta to access the arguments inside functions or methods, but is provided for user access, meaning it can be edited and stored as needed. Now, the expression ¦<expr>¦ within an a list of actual arguments is a directive to push onto the stack all elements of <expr> as follows:
<expr>[0], <expr>[1], ..., <expr>[N] for vectors (0...size()-1), objects (only numerically indexed elements with successive 0...tablength(a)-1 indices must exist) and lists (the elements are actually pushed front to back without indexing).
For instance, the call print("a", true, []); , can be also made as either t = [ "a", true, [] ]; print(¦t¦); or v = std::vector_new(3); v.push_back("a"); v.push_back(true); v.push_back([]); print(¦v¦); . This feature allows to store and supply arguments to calls dynamically, without requiring to syntactically enumerate the arguments as part of the invocation expression.
Below we provide a snapshot from a debug session where we inspect the contents of the 'p_hw' functor (function object) of our earlier example. As shown, the function-call operator appears as a normal slot for the (reserved) index '()', storing a method value.
|
|
|
***The function-call operator slot for a functor during a debug session*** |
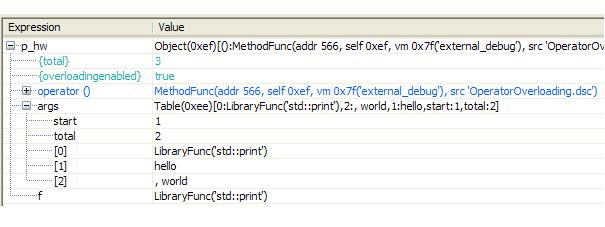
More information on function-call overloading as well as all the rest of operators is provided in the discussion on operator overloading.
Subobject trees
In Delta, untyped object-based inheritance is supported. In general, untyped object-based languages support inheritance with untyped mechanisms enabling the creation of webs of objects mimicking either the structure of typed class graphs, or the structure of typed subclass instances by making entire self-contained objects. The former concerns delegation, while the latter concerns subobject trees. The example below illustrates how subobject trees are constructed and how they behave in terms of slot access (lookup semantics).a = []; // an empty object b = [ { #x, #y : 10, 20 } ]; // a simple object with two slots 'x' and 'y' inherit(a, b); // we just set 'b' as the base subobject of 'a' print(a.x); // this resolves to 'b.x' since 'b' base of 'x' a.x = nil; // here we erase 'x' from more recent owner (removes 'b.x') print(b.x); // this will print 'nil' a.x = 10; // this 'x' slot is created locally at 'a' side b.x = -10; // but this also refers to 'a.x' (dot returns most recent version) print(a.x); // so this will print '-10' b..x = 10; // double dot accesses local slots thus we take 'x' at 'b' side print(a.x); // again 'a.x' is the most recent 'x' slot inherit(b, a); // runtime error, cycles are forbidden print(isderived(a, b)); // prints 'true' uninherit(a ,b); // we break the inheritance link between 'a' and 'b' print(isderived(a, b)); // thus now it prints 'false'A slightly more comprehensive example follows below, showing a subobject tree composed out of five distinct objects. Technically, subobjects are just normal objects, called subobjects to denote their participation in a tree which aims to emulate a subclass instance of class-based (typed) inheritance.
function New(id) { return [ @id: id ]; } inherit(b1 = New(#b1), a2 = New(#a2)); inherit(b1, a1 = New(#a1)); inherit(b2 = New(#b2), a3 = New(#a3)); inherit(c = New(#c), b2); inherit(c, b1);The resulting tree structure from this code snippet, as well as the ability to inspect the inheritance links among subobjects during debugging are illustrated below (the graphical tree is not displayed by the debugger, but was added manually to the debug session snapshot).
|
|
|
***Inspecting inheritance links among objects through the debugger*** |
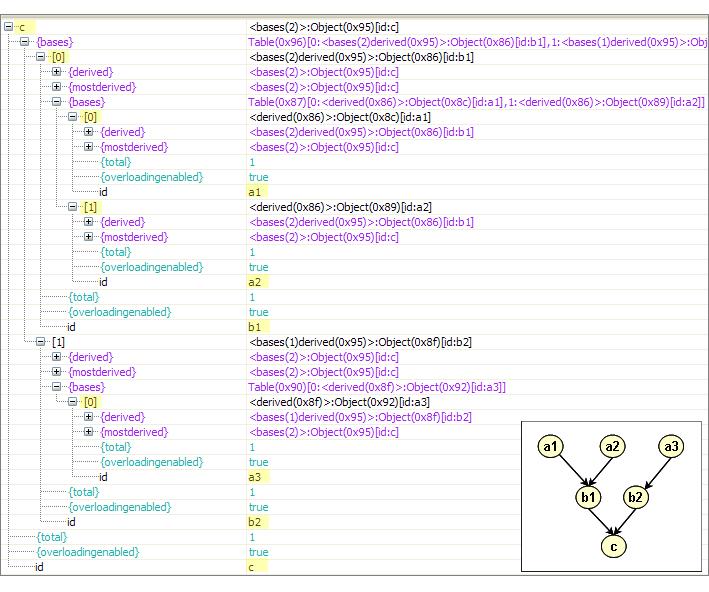
More information may be found on the elaborate discussion on subobject tress.
First-class virtual machines
In a Delta program one may load another compiled program (byte code) using a special set of library functions. Such a loaded program is handled through a virtual machine, a first-class value enabling to run the program (execute its global statements) and invoke or extract any global function. Thus, a virtual machine instance plays the role of a dynamically loaded library or package. A single program may be loaded multiple times into distinct independent virtual machines. Lets consider the example below with two sources, one playing the role of the library and another of the client prorgam://*************************************** // lib.dsc, playing the role of a package //*************************************** function foo // a 'foo' global function, visible outside { /* some code */ } function bar { // a 'bar' global function, also visible outside /* some code */ function f{} // an 'f' inner function, not visible outside } //*************************************** // client.dbc, playing the role of a client // Assume lib.dsc was compiled to lib.dbc //*************************************** lib_vm = vmload( // 'vmload' is the library function to load byte code "lib.dbc" // we load 'lib.dbc' into a new vm instance "lib" // 'lib' is the supplied vm id (has to be unique) ); vmrun(lib_vm); // vmrun executes global code is mandatory before using a vm lib_vm.foo(); // invokes 'foo' implemented in 'lib.dsc' print(lib_vm.bar); // all vm functions are normal functions (first-class values) lib_vm.f(); // runtime error, since only global functions are visible lib_vm.bar.f(); // runtime error, something like this is is not supported vm = vmget("lib"); // can get a vm instance by id from everywhere f = vm.foo; // we get 'foo' function value f(); // this works fine, it invokes 'foo' of 'lib' vm vmunload(vm); // with 'vmunload' we destroy a vm instance f(); // runtime error, since its vm instance was destroyed
It is very common for byte code loaded into virtual machine instances to concern functionality that is aimed to be used in a form of a shared dynamic library. In this case, although the vm API still suffices, the std::libs API is provided which requires less calls to handle registration, loading and sharing. The example below illustrates its use.
libs::registercopied(#lib, "lib.dbc"); // Register a copied lib (vm created on loading) from a file. libs::registercopied( // Register a byte code buffer as a copied library. #dyn_foo, std::inputbuffer_new( // Turn it to an input buffer std::vmcompstringtooutputbuffer( // Compile text code into a byte code buffer "function foo { throw \"foo\"; }", (function(err){ print(err,"\n"); }), false ) ) ); l1 = libs::import(#lib); // Loads and makes a new vm instances l2 = libs::import(#dyn_foo); // Loads only once and returns vm instance. l3 = libs::import(#dyn_foo); assert l2 == l3; // Because 'dyn_foo' is a shared library. l4 = libs::import(#lib); assert l4 != l1; // Because 'lib' is a copied library. try d.foo(); trap e { print(e, "\n"); } libs::unimport(l1); libs::unimport(l2); libs::unimport(l3); // Even when shared 'unimport' is needed (ref counted). libs::unimport(l4);
Apart from this sort of dynamic management of virtual machines, there is a special language feature that is more similar to 'import' like facilities met in other languages. More specifically, one may deploy the using #<ident>; directive which has the following effect: the file named '<ident>.dbc' is searched during compilation in all build paths. Once found, its function table (visible functions only) is loaded and all its functions become statically available to the program via <ident>::<func name> . Such loaded byte code is shared automatically if any other Delta program that is loaded in the same execution session happens to also use the same byte code file (thus they behave like automatically-loaded shared dynamic libraries). The example below demonstrates the way this directive can be used.
// File 'server.dsc' function foo {} function bar {} function local f {} // Hidden outside { function g {} } // Also hidden outside (non-global scope) // File 'client.dsc' using #server; server::foo(); // Ok, imported function visible. server::bar(); // Ok, imported function visible. server::f(); // Error, function not found in 'server' function table. vm = vmget(#server); // We can even get the vm of the library. vm.foo(); // Runtime lookup compared to server::foo which is at compile-time server::foo = 10; // Error, it is immutable. vm.f = nil; // Ok, just overwritten 'f' slot within vm's userdata.
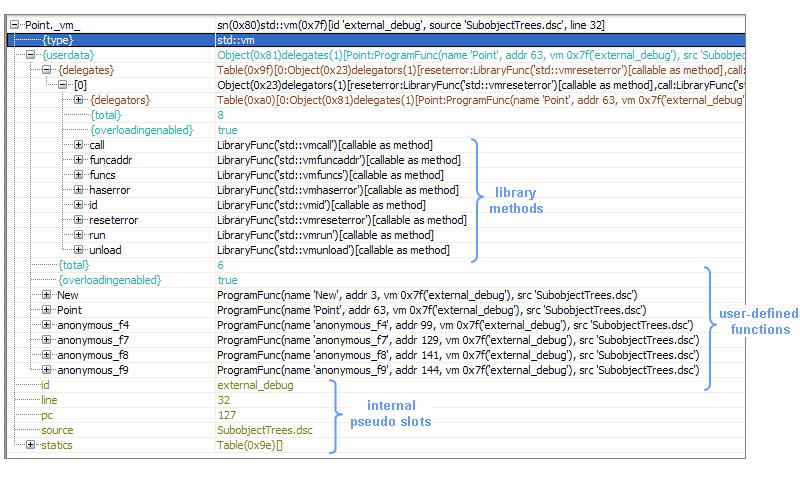
Below we provide a snapshot from a debug session where we inspect a virtual machine value. All built-in library functions for vms and all user-defined global functions of the loaded byte code, appear as slots within a 'userdata' reserved entry. In Delta, vms are native objects (they are implemented in C++). All native objects have a reserved 'userdata' entry that is an editable Delta object. Every operation that is allowed to Delta objects also applies to native objects by internal redirection to the 'userdata' object. Thus, developers of native objects may populate the 'userdata' entry with slots that have to be accessible from within Delta code. Also, used byte code files are loaded by the autocompletion mechanism of the Delta editor (in Sparrow), as shown in the picture below.
|
|
|
***Inspecting the 'userdata' entry of vm native values in a debug session*** |
|
|
|
***Autocompletion for byte code libraries in the 'using # |
More information may be found on the elaborate discussion on virtual machines.
Untyped attribute pattern
The attribute pattern appears in classes when there are pairs of methods with signatures: Set<id>(T) and T Get<id>() with <id> a property name, and T a type name. Languages like C# or ActionScript support this pattern by enabling class clients access such attributes through objects with the syntactic abstraction of field access like <inst>.<id> , while generating code to actually invoke the respective Set and Get methods. No support in classless languages for this pattern is met. However, in Delta an untyped dynamic version of the attribute pattern is fully supported . More specifically, let's check the example below:function Point(x, y) { return [ @x { // an 'x' attribute definition @set method(v) // defining the 'x' set method { @x = v; @xf(self); } // which invokes self.xf callback too @get method { return @x; } // defining the 'x' get method }, @y { // a 'y' attribute definition @set method(v) // defining the 'Y' set method { @y = v; @yf(self); } // which invokes self.yf callback too @get method { return @y; } // defining the 'y' get method }, { #xf, #yf : function(pt){} }, // empty implementations of listener callbacks { #x, #y : x, y }, // optional, but desirable, init values to 'x', 'y' method set_x_listener(f) // method to set the 'x' property listener callback { @xf = f; }, method set_y_listener(f) // method to set the 'y' property listener callback { @yf = f; } ]; } pt = Point(10,20); pt.x = 20; // internally invokes the set method pt.set_y_listener( // set a listere on 'y' function(pt){ print(pt.y); } // to actually print its value ); pt.y = -10; // will set 'y' to '-10' and print '-10' tabredefineattribute( // we can redefine the set / get methods pt, #x, function(v){}, // setter comes first (here it is nop) function{ return 0; } // getter follows (constantly returning 0). );Below we provide a snapshot from a debug session showing how detailed information for such attribute-type slots is fully provided. The snapshot is from a run of the previous example.
|
|
|
***Inspecting attribute details in a debug session*** |
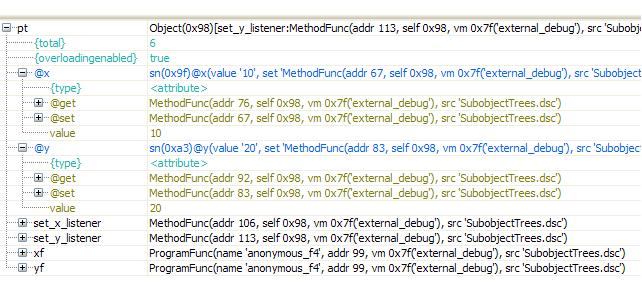
More information on attributes may be found on the programming guide.
Advanced embedding support
All components of the Delta language are implemented in C++, the later referred as the native language hereafter. The two basic modes of interoperation between Delta and native application code concern cross-language invocations as follows:Delta -> C++ (via library functions)
Library functions are implemented as C++ functions and are registered to the Delta runtime system, becoming available to Delta programs.
C++ -> Delta (via the virtual machine library)
(i) Using a virtual machine instance C++ programmers may extract and invoke directly Delta functions (parameter passing and extraction of the return value is naturally supported).
(ii) When a library function is called, the native application code may store any Delta value in its own structures. Such values may well be callable values, like functions, methods, function objects and library functions. The later may be directly invoked from within C++ code.
The example below shows how we can create a vm instance, load a Delta program, run it, catch any exceptions, test for any runtime errors and delete the vm after validating it was not already deleted by the running program. Notice that destruction of the current executing vm is possible in Delta by calling vmunload(vmthis()); after which execution will be stopped issuing also an error.
#include "Delta.h" DeltaVirtualMachine* vm; // Declare a vm ptr vm = DNEWCLASS(DeltaVirtualMachine, ("my_vm_id")); // Create a dynamic vm instance util_ui32 sn = vm->GetSerialNo(); // We record the unique vm serial no if (DPTR(vm)->Load("my_test.dbc")) // Load some byte code DELTA_EXCEPTIONS_NATIVE_TRY // Native try block block for Delta code DPTR(vm)->Run(); // Running the Delta program stmts DELTA_EXCEPTIONS_NATIVE_TRAP(e) // Native catch block for a Delta exception printf("%s\n", e.ConvertToString().c_str()); // Printing the exception value as string if (UERROR_ISRAISED()) { // Check for any execution errors printf("%s\n", UERROR_GETREPORT().c_str()); // Print the error report UERROR_CLEAR(); // We clear the error } if (ValidatableHandler::Validate(vm, sn)) // Is still a valid vm? { DDELETE(vm); unullify(vm); } // Delete vm and nullify ptrThe virtual machine class provides a comprehensive API for embedding support, part of which is provided below. Typically, manipulation of actual arguments and return value is needed when implementing library functions for Delta, while extraction of functions directly from a vm instance is needed when functions with predefined names, such as event handlers or callbacks, need to be invoked by native code.
// From DeltaVirtualMachine.h void PushActualArg (const DeltaValue); util_ui16 TotalActualArgs (void); DeltaValue* GetActualArg (util_ui16 argNo); void SetReturnValue (const DeltaValue val); const DeltaValue GetReturnValue (void) const; void ExtCallGlobalFunc (const char* name); void ExtCallGlobalFunc (DeltaCodeAddress funcAddr); void ExtCallMethodFunc (DeltaCodeAddress funcAddr, DeltaTable* table); void ExtCallFunction (DeltaValue* functor); bool GlobalFuncExists (const char* name); bool GlobalFuncExists (DeltaCodeAddress funcAddr); DeltaCodeAddress GlobalFuncAddress (const char* name); const char* GetFuncName (DeltaCodeAddress addr) const; DeltaCodeAddress ValidateFuncAddress (DeltaCodeAddress funcAddr, bool isMethod = false); DeltaValue* ValidateStackValuePtr (DeltaValue* val);The DeltaValue is the data structure for values manipulated by a Delta program. It supports all Delta types, thus realizing a dynamically-typed value, and it offers a comprehensive API for reading, assignment, construction, and invocation (in case it is a callable value). Part of this API is provided below.
// From DeltaValue.h //******GETTERS*******/ const std::string ToString (void) const; DeltaNumberValueType ToNumber (void) const; DeltaLibraryFunc ToLibraryFunc (void) const; bool ToBool (void) const; DeltaTable* ToTable (void); void ToProgramFunc ( DeltaCodeAddress* funcAddr, DeltaVirtualMachine** vm, util_ui32* serialNo = 0 ); void ToMethodFunc ( DeltaCodeAddress* funcAddr, DeltaTable** table, DeltaVirtualMachine** vm, util_ui32* serialNo = 0 ); DeltaTable* GetMethodSelf (void); util_ui32 ToExternIdSerialNo (void) const; void* ToExternId (std::string typeStr); void* ToExternId (void); DeltaTable* GetExternIdUserData (void); const std::string GetExternIdTypeString (void) const; //******SETTERS*******/ void FromNumber (DeltaNumberValueType num); void FromString (const std::string s); void FromBool (bool boolVal); void FromTable (DeltaTable* table); void FromExternId ( void* val, DeltaExternIdType type = DeltaExternId_NonCollectable, void (*toString)(DeltaString*, void*) = 0, const char* typeStr = 0, const DeltaExternIdFieldGetter* fieldGetter = 0 ); void FromExternIdBySerialNo (util_ui32 serialNo); void FromLibraryFunc ( DeltaLibraryFunc func, DeltaLibraryFuncArgsBinder* binder = (DeltaLibraryFuncArgsBinder*) 0 ); void FromProgramFunc (DeltaCodeAddress funcAddr, DeltaVirtualMachine* vm); void FromMethodFunc ( DeltaCodeAddress funcAddr, DeltaTable* table, DeltaVirtualMachine* vm ); void ChangeMethodSelf (DeltaTable* table); void FromNil (void); void Undefine (void);To demonstrate the ease of invoking Delta functions from within native code, we discuss a quick and simple example. Lets consider a native callback OnSceneEntered(const std::string sceneId) invoked by a game application whenever a new scene is entered. Assume a virtual machine instance with identifier "game_vm" carrying the code for handling such application-specific events, assuming global Delta functions are optionally defined with the same name. Then, this is how we can redirect the callback invocation directly to Delta code:
<some_return_type> <some_class>::OnSceneEntered (const std::string sceneId) { if (DeltaVirtualMachine* vm = VMRegistry().Get("game_vm")) // get vm if (DeltaCodeAddress f = vm->GlobalFuncAddress("OnSceneEntered")) // get function if (DeltaValue(f,vm)(sceneId)) // make func value and call handle_error_in_delta_code_here; // runtime error occured }The previous is possible due to the overloaded constructors and the overloading of the function call operator offered by the DeltaValue class. When a callable Delta value is invoked, as in the example, it passes all supplied arguments to the respective vm stack, invokes the function, then retrieves and returns the result. The relevant API is shown below:
// From DeltaValue.h //******FUNCTION CALL OVERLOADING*******/ // Arguments in normal order for methods below. #define DARG const DeltaValue bool operator()(DeltaValue* result = (DeltaValue*) 0); // Argumentless bool operator()(DARG arg1, DeltaValue* result = (DeltaValue*) 0); bool operator()(DARG arg1, DARG arg2, DeltaValue* result = (DeltaValue*) 0); bool operator()(DARG arg1, DARG arg2, DARG arg3, DeltaValue* result = (DeltaValue*) 0); bool operator()(DARG arg1, DARG arg2, DARG arg3, DARG arg4, DeltaValue* result = (DeltaValue*) 0); #undef DARG // Arguments in reverse order for methods below. bool operator()(const std::list<DeltaValue> args, DeltaValue* result = (DeltaValue*) 0); bool operator()(UPTR(const DeltaValue)* args, util_ui16 n, DeltaValue* result = (DeltaValue*) 0); bool operator()(UPTR(const DeltaValue)* nullEndingArgs, DeltaValue* result = (DeltaValue*) 0); //******CONSTRUCTORS*******/ DeltaValue (void); DeltaValue (const DeltaValue val); DeltaValue (_Nil); DeltaValue (const std::string s); DeltaValue (bool b); DeltaValue (DeltaNumberValueType n); DeltaValue ( void* val, DeltaExternIdType type = DeltaExternId_NonCollectable, void (*toString)(DeltaString*, void*) = 0, const char* typeStr = 0, const DeltaExternIdFieldGetter* fieldGetter = 0 ); DeltaValue (DeltaTable* t); DeltaValue (DeltaLibraryFunc lf, DeltaLibraryFuncArgsBinder* binder = 0); DeltaValue (DeltaCodeAddress pf, DeltaVirtualMachine* vm); DeltaValue (DeltaCodeAddress mf, DeltaTable* t, DeltaVirtualMachine* vm);More information may be found on embedding support.
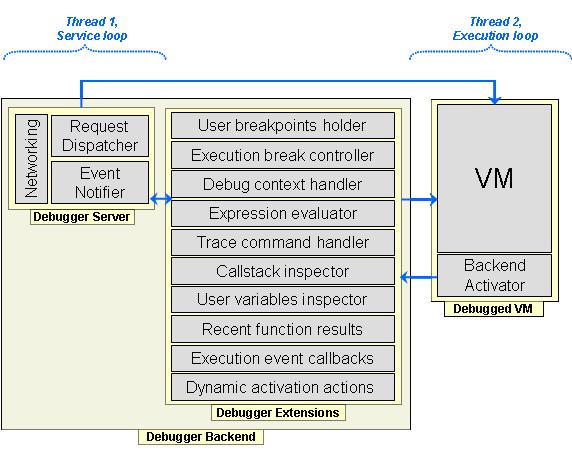
Complete debugger architecture
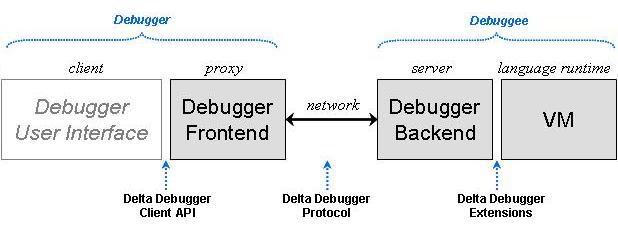
The development of a debugger entails primarily three key components: (a) the debugger backend, being usually language or platform dependent; (b) the debugger frontend, being in most cases tied to a specific backend; and (c) the debugger user interface that has to deploy a specific frontend. The debugger backend is a lower-level language subsystem enabling to control and inspect a program's execution (debuggee), while the frontend is a higher-level API for backend functionality aiming to support debugger user-interfaces (clients). The Delta language includes the thorough implementation of a debug architecture being outlined in the following figure. This architectural style is similar to the JPDA, since it adopts a physical split among the debugger backend and frontend.|
|
|
***Overview of the Delta Debug Architecture (DDA)*** |
The detailed architecture of a debugee in Delta is shown in the following figure. What is apparently missing is a thread manager module, since, currently, the Delta language lacks support for threads. The backend may be explicitly included in the build image of a program, in which case a debug session may be initiated / terminated at any point, and as many times needed, during runtime. However, when not included, meaning the executable lacks a debugger backend, it will be loaded dynamically by Delta in case of runtime error, in order to allow users start a debug session and trace the bug. Besides the basic features, the DDA supports more advanced features such as:
- Selective step-in for lines with multiple / nested calls
- Conditional breakpoints
- Return values of local calls during tracing
- Support for object monitors
- Extraction of variables in current context
- Incremental query for aggregates
- Extraction of object graph with a depth parameter
|
|
|
***Detailed debugeee architecture in Delta Debug Architecture (DDA)*** |
The frontend API is to be deployed by developers of debugger user-interfaces. Practically, this is rarely required, since Delta is already accompanied with two powerful debugger user-interfaces: (a) Disco , a console-based standalone debugger; and (ii) Zen , a graphical debugger embodied within the Sparrow IDE of the Delta language. Below we show part of the frontend API.
// From DebugClient.h static void Initialise (void); static bool Connect (const std::string host, util_ui32 port); static void CleanUp (void); /////////////////////////////////////////////////////////////////////////// // REQUESTS // Trace control ********************************************************** static void DoGo (void); static void DoStepOver (void); static void DoStepIn (void); static void DoGetAllPossibleCalls (void); static void DoSelectiveStepIn (util_ui32 callOrder); static void DoRunTo (util_ui32 line); static void DoStepOut (void); static void DoStart (void); static void DoStop (void); static void DoBreakExecution (void); // Variable / expression value request and string conversion size ********* static void DoGetExpr (const std::string expr); static void DoGetExprMany (const std::list<std::string> exprs); static void DoGetExprTypeData (const std::string formatId, const std::string expr); static void DoGetExprTypeDataMany (const std::string formatId, const std::list<std::string> exprs); static void DoGetObjectGraph (const std::string expr, util_ui32 depth); static void DoGetVariables (void); // At current context. static void DoSetToStringMaxLength (util_ui32 maxLen); static void DoGetDynamicCode (void); // In case source code was produced at runtime. static void DoAssignExpr (const std::string lvalue, const std::string rvalue); // Context control ******************************************************** static void DoStackUp (void); static void DoStackDown (void); // Break point control **************************************************** static void DoAddBreakPoint (const std::string source, util_ui32 line, const std::string condition); static void DoChangeBreakPointCondition (const std::string source, util_ui32 line, const std::string condition); static void DoRemoveBreakPoint (const std::string source, util_ui32 line); static void DoEnableBreakPoint (const std::string source, util_ui32 line); static void DoDisableBreakPoint (const std::string source, util_ui32 line); static void DoEnableAllBreakPoints (const std::string source); static void DoDisableAllBreakPoints (const std::string source); static void DoRemoveAllBreakPoints (const std::string source); /////////////////////////////////////////////////////////////////////////// // RESPONSES AND NOTIFICATIONS static bool GetInfoStopPoint ( std::string* source, util_ui32* line, bool* isGlobal, std::string* cond ); #define GetInfoInfoBreakPointConditionError GetInfoInvalidBreakPoint static bool GetInfoInvalidBreakPoint ( std::string* source, util_ui32* line, // The break point requested. util_ui32* newLine, std::string* cond // Condition, if no condition. ); static bool GetInfoValidBreakPoint ( // Returns the original data supplied when adding. std::string* source, util_ui32* line, std::string* cond ); static bool GetInfoCurrFunction ( std::string* func, util_ui32* defLine, // If 0, it means it is an extern function. util_ui32* callLine, util_ui32* scope, std::string* call ); static bool GetInfoValue (std::string* content); static bool GetInfoDynamicCode (std::string* source); static const std::string GetDynamicCodeVirtualPath (const std::string vmId); static bool GetInfoValueMany (std::list< std::pair<std::string, bool> > contents); static bool GetInfoExprTypeData (std::string* content); static bool GetInfoExprTypeDataMany (std::list< std::pair<std::string, bool> > contents); static bool GetInfoObjectGraph (ObjectGraph graph); static bool GetInfoErrorValue (std::string* error); static bool GetInfoError (std::string* error); static bool GetInfoBreakPointError (std::string* error); static bool GetInfoWarning (std::string* error); static bool GetInfoVariables ( // In current context std::list< std::pair<std::string, std::string> > vars ); static bool GetInfoAllPossibleCalls ( // For selective step-in std::list< std::pair<std::string, std::string> > calls ); static bool GetMostRecentFuncResults ( // For return values of recent local calls std::list< std::pair<std::string, std::string> > results );More information may be found on implementation architecture.
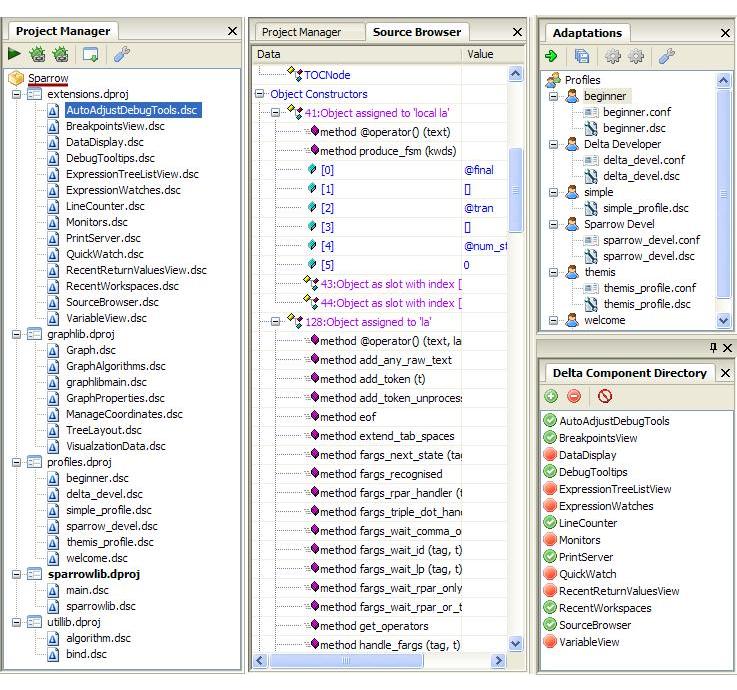
Powerful self-extensible IDE
The Delta language is accompanied with a full-fledged IDE named Sparrow which is build around a component-based architecture enabling introduce new components as typical plug-ins. Such components can be implemented in two languages. The first option is C++, being the language in which the IDE is actually programmed. In this case new components are characterised as native extensions . The second, and more interesting option, is to program them directly in Delta using the IDE they actually extend. For this reason such extension components are characterised as circular extensions . The IDE currently encompasses a large number of circular extensions, all collected under a workspace named 'Sparrow' (there is no requirement for users to put any future circular extensions under the same workspace, but it is suggested for convenience to do so). All cirular extensions can be source-level debugged using the IDE itself through a feature known as circular / self debugging . Below we provide a list of various features supported by our Sparrow IDE:
- Project manager (workspace and projects)
- Editor with syntax highligher (marks syntax errors too)
- Source-level debugger
- Source browser (as a circular extension)
- Introspection window for active components (enabling invocation)
- Configurations for individualised use (called adaptations)
- Self-debugging for circular extensions (via two running IDE instances)
|
|
|
*** Various standard components of the Sparrow IDE *** |
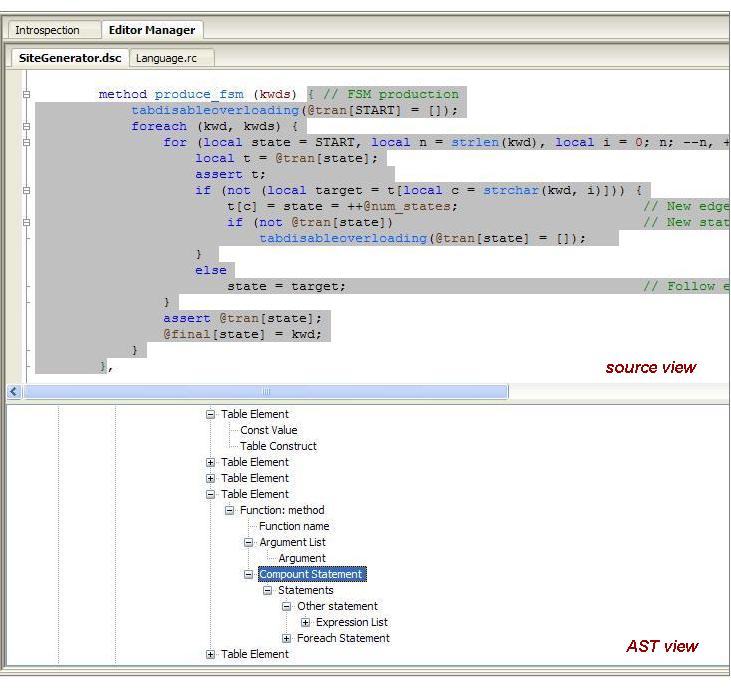
Another interesting feature helping to learn and understand more quickly the Delta language syntax is the split view of the source code and its respective AST, as shown in the picture below. In particular, if we click on a node of the AST, the editor will immediately highlight the respective text segment.
|
|
|
*** Split view of the source editor and the respective AST *** |
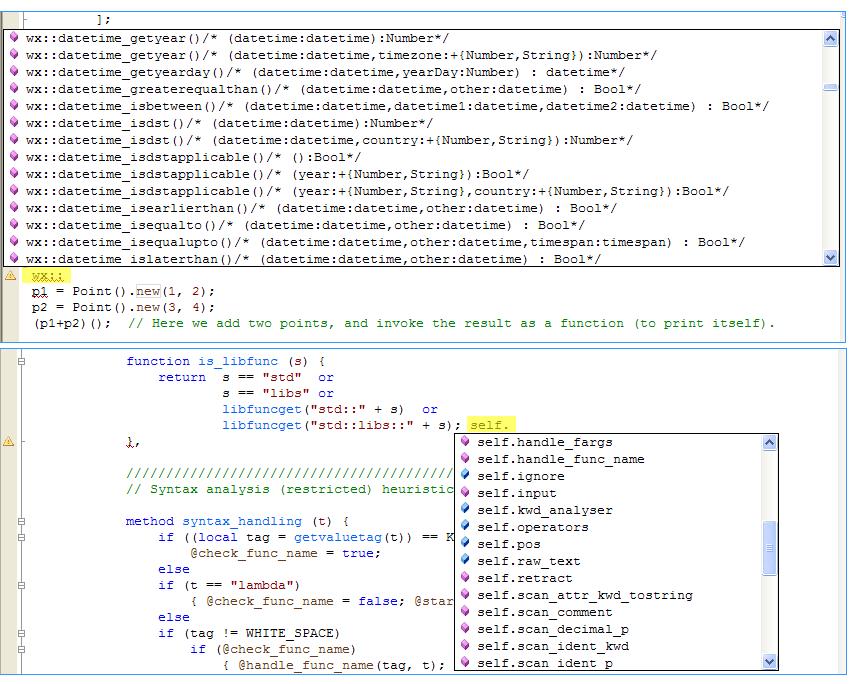
Our source editor is built on top of Scintilla, meaning many powerfull features are offered, like zooming and code folding. Additionally, at the current implementation which does not include an IntelliSense component, our auto-completion features are restricted to library items (namespaces, functions and constants) and self object slots.
|
|
|
*** Auto-completion editor features *** |
More information may be found on the main section about the IDE.
Objects and methods
n = 10, m = 20; a = [ { "x" : 1 }, // data slot with index 'x' and value 1 { (n+m) : 2 }, // data slot with index 30 and value 2 { #y : 3 }, // data slot with index 'y' (#<id> is stringify) and value 3 @z : 4, // data slot with index 'z' as @<id> : expr is sugar for {#id : expr } { .w : 5 }, // data slot with index 'w' (.<id> as index same as "<id>") and value 5 { #k, #l, #m : 6 }, // three data slots 'k', 'l', 'm' all with value 6 { (function g{}) : list_new(1,2,3) }, // data slot with index function g and value a list { l = list_new() : [] } // data slot with index a list and value an empty obj ]; l.push_back(); // vars can be defined inside object ctors (the latter do not affect the scope) a[g].push_back(4,5,6); // indexing with a function is perfectly legal. a[l][0] = 20; // as seen, all Delta values can be used as object indices.
Normally, object creation will pertain to a designed class, with the exception of objects that are simply needed to carry a few methods and some data that do not necessarily map to a class in the conceptual domain. These are 'objects on demand' which are created ex nihilo as needed. To model a class we can use constructor functions, also known as factory methods. Such functions take the name of their design-domain class. In some languages they are semantically distinguished as in Javascript (they imply classes which may help in autocompletion tools or even in optimization - the Javascript V8 engine relies on that). In Delta they are just normal functions. An example is provided below:
function Student (name, address, age) { return [ @name : name, @adress : address, @age : age, method rename (s) { self.name = s; }, // the simplest syntactic form @rename : (method (s) { self.name = s; }), // this alternative also supported { "rename" : (method (s) { self.name = s; }) } // both are syntactic sugar for this ]; } st1 = Student("John", "Singleton", 42); st2 = Student("Robert", "Rodriguez", 39); st2.rename("Maria"); r1 = st1.rename; // method values carry their owner internally r1("Anna"); // thus this is equivalent to st1.rename("Maria") r1.self = st2; // but we may alter the owner dynamically r1("Jose"); // hence this call is performed on 'st2' r1.self = []; // can even redirect to a new object r1.self = nil; // runtime error: cannot strip-off owner entirely
Besides methods explicitly declared within object constructors, orphan methods are also supported in Delta. Combined together with the ability to change the owner (self), it allows flexibly assemble method suites on demand, by optionally reusing existing methods in a non-intrusive and dependency free manner (unlike inheritance). Naturally, the methods will behave correctly once invoked with a self providing an appropriate context for all self-related references. An interesting spin-off gain of the ability to redirect methods to other objects is that such objects remain ignorant of the fact other methods refer to them; this allows add behavior on objects in a totally transparent way. Lets consider the example below:
using std; method dist (a) // what is an 'a' or self ? anything offering (x,y) slots { return sqrt(sqr(self.x - a.x) + sqr(self.y - a.y)); } vec3d = [ { #x, #y, #z : 0 } ]; // x, y, z slots, all initialised to 0 pt2d = [ @x : 1, @y : 2 ]; // x, y slots with initial values 1 and 2 dist.self = pt2d; // 'dist' uses 'pt2d' as owner which has no idea about it print(dist(vec3d)); // here it is called standalone, again 'pt2d' is not aware pt2d.dist = dist; // but now we explicitly add a slot with value 'dist' pt2d.dist(pt2d); // now called as a method of 'pt2d'
Copy on objects is possible by using std::tabcopy(a) library function accepting an object and returning a shallow copy of it. Method values whose owner is the copied object 'a' are copied by setting as new owner the newlly created object. An example is provided below:
using std; a = [1, 2, 4, @x : "hello", method f(s) { self.x = s; } ]; b = tabcopy(a); print(a.x); // prints 'hello' a.f("world"); // change applied on 'a' print(a.x); // prints 'world' print(b.x); // prints 'hello' b.f("universe"); // change applied on 'b' print(b.x); // prints 'universe' method g { print(self.x); } // orphan method print(g.self); // this is an empty object a[0] = g; // just store the method value in [0] c = tabcopy(a); // shallow copy assert c[0].self != c; // the copied method retains its owner c[0](); // will print nil, since no 'x' slot in g.self c[0].self = c; // we redirect it to have 'c' as owner c[0](); // prints 'world' ('x' slot of 'c' object)
Iteration is possible either by using the std library ( tableiter_ functions), or by using a foreach loop. The iteration order is implementation defined, thus the programmer should not rely on that. Also, iteration in foreach is safe even when the current iterator is removed. Examples follow below:
st = Student("James", "Cameron", 64); foreach(val, st) // loop on values (keys remain hidden), 'val' is user-defined var print(val); foreach (key:val, st) // loop on keys and values, 'key' a user-defined var too print(key, ":", val); a = []; foreach (a.key : a.val, st) // the key and value place holders are just lvalues print(a.key, ":", a.val);
In case the newlly created object must be used during construction the @self keyword (new self) can be used for this purpose. It is allowed only within, and in the same scope as object construction expressions. While it can be normally used to access methods or data slots care must be taken since at the point of use the object may be only partially created, thus not all members are available for access. Examples follow below:
a = [ @x : 1, @name : "shreck", @world : @self.name + " for ever", // 'name' slot has been created (safe) method act { print("play the role!"); return self; }, @y : (lambda(a){ a.act().x })(@self), // calls lambda calling 'act' on new self (safe) @z : @self.sequel(), // calls 'sequel' on new self (fails, 'sequel' not yet added) method sequel { return @world + " after"; } ];
Metaprogramming
Introduction
The term metaprogramming is generally used to denote programs that generate other programs and was originally related to the existence of a macro system like the C Preprocessor (CPP) or the Lisp macro system that would allow program fragments to be built up at compile-time. Lexical systems like the CPP are recognized as being inadequate for metaprogramming as they operate on raw text, unaware of any context information, while most languages do not share Lisp's syntactic minimalism to provide an equally powerful facility with seamless integration.In modern languages, metaprogramming is closely coupled with functions that operate on some abstract syntactic form, like an abstract syntax tree (AST), and can be invoked during compile-time to change existing code or introduce additional code in the source file that is being compiled. Such functions are called metafunctions and they as a whole constitute the metaprogram. The compilation of a program that contains a metaprogram requires the metaprogram to be executed at compile-time to produce a possibly changed source file that will then be compiled. If the resulting source contains additional metaprograms they are executed in the same way until we reach a final source with no metaprograms that will be compiled into the final executable. This iterative process may involve multiple steps of metaprogram evaluations called stages, while languages that support such a compilation scheme are called multi-stage languages. Multi-stage languages use special syntax, called staging annotations, to explicitly specify the evaluation order of the various computations of the program, with respect to the stage they appear in.
Staging annotations
Delta supports multi-stage metaprogramming through the following staging annotations:Quasi-quotes (written ... ) may be inserted around definitions, such as expressions, statements, functions, etc., to convey their AST form and are the easiest way (but not the only one) to create ASTs directly from source text. For instance, 1+2 is the AST for the source text 1+2 . Variables within quasi-quotes are scoped in the context where the respective AST is finally inserted. For instance, x=1 does not bind to any x visible at the quasi-quote location. It will bind to an existing x at the insertion context, or if no x is defined there, introduce a new x in scope (in Delta variables are declared-by-use). To prevent variable capture we allow quasi-quotes to introduce alpha-renamed variables (i.e., given automatically contextually-unique names) using special syntax. In particular, x denotes that x will be given a fresh unique name at the insertion context. Finally, we allow quasi-quotes to be arbitrarily nested, something useful in higher order metaprograms (e.g. when implementing metagenerators). For example, 1+2 is a nested quasi-quoted expression whose generation produces the quasi-quoted expression 1+2 . Further quasi-quote examples are provided in the code below.
x = 1+2; // x get a value + // representing the / \ // tree on the right 1 2 y = 1, true, "str", [1, 2]; // represents a list of items that can be used // as an argument list or as table elements z = // represents the AST of the entire for loop for(i = 0; i < 5; ++i) std::print(i); ; u = // represents the AST of the entire function function add(x,y) { return x + y; } ; v = // represents a list of statements a = 1; try { while(a > 0) f(a--); assert a == 0; } trap ex { std::print(ex); } ; w = 1+2 ; // a nested AST value (AST representing an AST) q = x = 1; // variable x will not bind to an existing x at the // insertion context, but is automatically renamed
Escape (written (expr) or id ) is used only within quasi-quotes to prevent converting the source text of expr into an AST form by evaluating expr normally. Practically, escape is used on expressions already carrying AST values which need to be combined into an AST constructed via quasi-quotes. For example, assuming x already carries the AST value of 1 , the expression x+2 evaluates to 1+2 . Additionally, we also support the escaped expression to carry scalar values like number, boolean or string (i.e. ground values). In this case, the value is automatically converted to its corresponding AST value as if it has been a constant. For instance, if x is 1 , then x within x+2 will be converted to the AST of value 1 , or 1 , thus x+2 evaluates to 1+2 .
In case of nested quasi-quotes, escapes are evaluated during the construction of the outermost quasi-quote, meaning that if x is 1 , the expression x+2 evaluates to 1+2 . In order to delay the evaluation of an escape (something useful in metagenerators), we can use a delayed escape , denoted as ...(expr) . For example, writing x represents the AST of x . The number of tildes is the initial nesting which for normal escapes is one. Then escape evaluation, being performed when quasi-quotes are constructed, is applied as follows:
eval(escape(n, expr) = if n is 1 then expr else escape(n - 1, expr)
Notice that the previous evaluation is not recursive; it returns either the escaped expression or a new escape with decreased nesting. Practically, this means that a delayed escape will eventually be inserted in a generated quasi-quote as a normal escape and then follow its normal evaluation.
The code below shows some examples relating to escapes, while examples highlighting the use of delayed escapes will be discussed once the staging tags and stage assembly are fully explained.
x = 1; y = x + 2; // y is <<1 + 2>> z = x + y * 3; // z is <<1 + (1 + 2) * 3>> function id(x) { return x; } v = (id(1)) + (id(2)); // v is <<1 + 2>> num = 1, str = "hello", bool = true; w = num, str, bool; // escapses also support ground values, automatically // converting them to ASTs, so w is <<1, "hello", true>> function pow(x, n) { // will generate the AST of multiplying x with itself n times if (n == 0) return 1; // termination: just multiply with 1 (in AST form) else return x * (pow(x, n-1)); // recursion: multiply x with the result of the recursive invocation } pow3 = pow(x, 3); // pow3 is <<x * x * x * 1>> args = 2, 3; call1 = f(args); // call1 is <<f(2, 3)>> call2 = f(1, args, 4); // call2 is <<f(1, 2, 3, 4)>> call3 = f(args) ; // escapes also apply for nested quotes, so call3 is << <<f(2,3)>> >> t1 = [1, args, 4]; // t2 is <<[1, 2, 3, 4]>> empty_ast = nil; // nil is used to denote an empty AST t2 = [1, empty_ast, 4];// escaping a nil value removes the entire node, so t2 is <<[1, 4]>> call4 = f(empty_ast); // similarly, call4 is <<f()>> function func_generator(name, args, body) { return function name (args) { body; }; } f = func_generator(id, x, return x;); // f is <<function id(x) { return x; }>> a = x; // the AST contains variable that will be automatically renamed b = a + a; // such variables are preserved by escapes, so b is <<$x + $x>> stmts = list_new( // a list of statements as AST values. x = 1;, while(x > 1) f(--x);, assert x == 0; ); // to combine them into a single AST we can do the following: code = nil; // initially we have no code, so code is nil foreach(local stmt, stmts) // iterate over all statements in the list code = code; stmt;; // append each statement at the end of the already existing code // finally, code is << // x = 1; // while(x > 1) // f(--x); // assert x == 0; // >>
Inline (written (expr) ) evaluates the expr during translation and inserts its result (that must be of AST type) into the program code by substituting itself, thus performing program transformation. Inline tags within quasi-quotes are allowed, and as all other quasi-quoted expressions, are just AST values and are not directly evaluated. It is allowed for expressions carrying an AST representing an inline directive to be inlined, meaning generation directives may generate further generation directives, thus supporting metagenerators. The following examples illustrate the usage of inline.
(a = 1); // inserts the statement a = 1 directly into the program source b = (1+2); // equivalent to b = 1 + 2; c = (f()); // equivalent to c = f(); function one() { (return 1;); }// equivalent to function one() { return 1; } function id(x) { return x; } (id(d)) = (id(1)) + (id(2)); // equivalent to d = 1 + 2; function func_generator(name, args, body) { return function name (args) { body; }; } (func_generator(add, x, y, return x+y;)); // will generate the following function: // function add(x, y) { return x + y; } y = (for(i = 0; i < 1; ++i);); // error, generating a statement but expecting expression function pow(x, n) { if (n == 0) return 1; else return x * (pow(x, n - 1)); } print((pow(2, 3))); // equivalent to print(2 * 2 * 2 * 1); ( print((pow(2, 3))); ); // metagenerator for the above statement function f(n) { if (n < 1) return nil; else return (f((n - 1))); // returns an AST that when inlined will cause further staging } (f(10)); // generates !(f(9)) that will then generate !(f(8)) and so on // until the last step that eventually generates no code (nil) // it involves 10 evaluation rounds (i.e. stages) to complete function f() { return (f()); } (f()); // repeatedly generates itself, causing endless staging
Execute (written stmt ) defines a staged stmt representing any single statement, local definition or block in the language. Any definitions introduced are visible only within staged code. As with the other annotations, execute tags can also be quasi-quoted to be converted to AST form. This means that they are not evaluated directly, but when inlined they will introduce further staging (metageneration). Examples using execute are shown in the code below.
function ExpandPower (n, x) { // function is available only during compilation if (n == 0) return 1; else return x * (ExpandPower(n - 1, x)); } function MakePower (n) { // function is available only during compilation return ( function (x) { return (ExpandPower(n, x)); } ); } power3 = (MakePower(3)); // generates: power3 = (function(x){ return x * x * x * 1; }); // all previous declarations never appear in the final program x = 1, y = 2, z = nil; // x, y, z are available during compilation (compile-time state) if (some_condition()) // the if statement is executed during compilation with all z = x; // compile-time state being available to it else // execute tags are also evaluated in order of appearance, z = y; // so they provide the notion of typical control-flow print((z)); // inlines are also evaluated in order and can access compile-time state // the generated code depends on the result of the some_condition() print("hello"); // executed during compilation, prints 'hello' at compile-time (print("hello");); // metagenerator for the above statementFrom the staging annotations discussed, quasi-quotes and escape involve no staging but are essentially facilities helping programmers in AST manipulation. As shown in the following table, quasi-quotes are essentially shortcuts for AST creation (ast_create) and escapes involve AST composition operations (ast_escape), all handled in our language with internal parser invocations.
| AST tag expressions | Respective intermediate code |
| 1 + g(); | ast_create $0 "1 + g()" |
| (f(x)) + 2; |
param x
call f getretval $0 #carries f(x) ast_create $1 "~(f(x)) + 2" ast_escape $1 $0 #inserts f(x) |
| x | ast_create $0 "<< ~~x >>" |
| x + y |
ast_create $0
"<< ~~x + ~y>>"
ast_escape $0 y #inserts y |
| f(a, b) |
ast_create $0
"f(~a, ~b)"
ast_escape $0 a #inserts a ast_escape $0 b #inserts b |
Both inline and execute tags can also be nested (e.g. ((expr)) or stmt ), with their nesting depth specifying the exact compilation stage they will appear in. As a rule of thumb (the exact semantics will be discussed in the following section), the higher the nesting of inline or execute tags, the sooner they are evaluated during compilation. This is illustrated in the following example.
(( x = 1 ); // the inner inline is evaluated first generating: !(<<x = 1>>); // that is then evaluated to generate the final x = 1; print(1); // the higher the nesting, the sooner the execution, so despite the print(2); // original order, this will first execute &&&print(3), then &&print(2) print(3); // and finally &print(1), meaning the compile-time output is 3, 2, 1
Stage assembly
Delta introduces the integrated metaprogramming model, treating distinct meta-code fragments as a single coherent metaprogram. In this sense, each stage is composed by assembling source fragments from specific staging tags within the main program AST. Their selection relies on the nesting level of staging tags and reflects two basic rules:(i) source fragments of tags with larger nesting depth are evaluated before those of smaller nesting depth
(ii) source fragments of tags with identical nesting depth are evaluated together in the same stage.
This practically means that to assemble a stage we have to collect all source fragments from the staging tags of the maximum nesting depth (i.e. the innermost).
The stage composition begins by traversing the program AST to find its maximum staging nesting. Then we perform a depth-first traversal and collect all source fragments belonging to staging tags with this maximum nesting. For execute tags the stmt source is added, and the tag is removed from the main program AST. This ensures that the specific source fragments only take part in the composition of the current stage. For inline tags, an std::inline call is added with argument the associated expr. This function is available only during compilation and handles the insertion of source fragments (as ASTs) to the main program AST. While expr is removed from the main program AST, an orphan inline leaf node is retained so that it can be used as a marker of the position where the next insertion from std::inline will occur. The latter supports having multiple inlines in the same stage nesting, thus resulting in multiple std::inline calls in the stage and orphan inline nodes in the AST. The std::inline calls and inline nodes are created during the same traversal so that they perfectly match each other during stage evaluation.
After all source fragments relevant to the current stage are collected, they are assembled together following their order of appearance in the main program. Then, the resulting program, that by construction contains no staging tags, is normally compiled to produce the stage binary which is executed to perform the respective source code transformations.
For example, consider that we have the following source:
Original Source
function generator(name, args, body) { return function name(args) { body; } ; } (generator( const_maker, name, val, return function name { return val;}; )); (const_maker(one, 1)); print(one()); (const_maker(two, 2)); print(two());It contains staged code with maximum nesting depth 2, the generator function and its corresponding invocation. As previously mentioned, only & and ! tags count towards the nesting depth.
After collecting all source fragments with the maximum nesting depth, the first stage is assembled as:
Stage 1 (Nesting depth 2)
function generator(name, args, body) { return function name(args) { body; }; } std::inline(generator( const_maker, name, val, return function name { return val;}; ));After compiling and executing the first stage, std::inline will insert the AST resulting from the generator function invocation, thus transforming the original source as follows. Also notice that the entire definition of function generator has been removed from the transformed source as it was meant to be available only for the nesting depth 2.
Intermediate Source
function const_maker(name, val) { return function name { return val; }; } (const_maker(one, 1)); print(one()); (const_maker(two, 2)); print(two());The transformed source still contains staged code so the staging process continues. Here, the maximum nesting depth is 1, present in the definition of function const_maker and its following invocations. This way, the second stage is assembled as:
Stage 2 (Nesting depth 1)
function const_maker(name, val) { return function name { return val; }; } std::inline(const_maker(one,1)); std::inline(const_maker(two,2));When executed, the two std::inline invocations will transform the main AST (and thus the intermediate source version) by inserting the corresponding ASTs produced by the const_maker function calls. Each call inserts code directly in the location of the original corresponding inline tag. The resulting source is as follows:
Final Source
function one { return 1; } print(one()); function two { return 2; } print(two());The transformed source contains no further staged code, so it has reached its final form and can be normally compiled to produce the final binary. The result of the entire compilation is as though the original program contained the code shown above.
Apart from the source code insertions performed by the std::inline invocations, Delta also offers an additional compile-time function called std::context that enables metaprograms to obtain and manipulate the actual context of any inline annotation, thus supporting context-aware generation and transformation. In particular, the std::context function locates and returns the orphan inline AST node in which the next inline will actually occur.
For example, consider a class definition with data members for which we wish to automatically generate setter and getter functions. Instead of separately introducing inline tags for each data member and explicitly supplying their names, we can utilize std::context to obtain the AST of the class definition, traverse the AST to obtain member information and then:
(i) directly attach to the AST the required method definitions; or
(ii) produce the AST for the method definitions, and inline its returned value where desired.
Both options for context-aware code generation are illustrated in the following example.
function SettersAndGetters1(class) { foreach (local attr, class.getAttributes()) { //iterate over class attributes local name = attr.getName(); local setter = method ("set_" + name)(val){self[name]=val;}; local getter = method ("get_" + name)(){return self[name];}; class.addMethod(setter); //add setter and getter methods directly to target class class.addMethod(getter); } return nil; //no additional code to be inlined in the target class } function SettersAndGetters2(class) { local result = nil; //will hold the generated method code tobe inlined in the class foreach (local attr, class.getAttributes()) { //iterate over class attributes local name = attr.getName(); local setter = method ("set_" + name)(val){self.name=val;}; local getter = method ("get_" + name)(){return self.name;}; result = result, setter, getter; // combine methods in a new AST } return result; //all setter and getter methods will be inlined in the target class } function Point(x, y) { return [ @x : x, @y : y, (SettersAndGetters1(std::context("class"))); //or !(SettersAndGetters2(std::context("class"))); //both invocations transform the Point class as shown below: ]; } //function Point(x, y) { // return [ // @x : x, @y : y, // method set_x(val){ self.x = val; }, // method get_x() { return self.x; }, // method set_y(val){ self.y = val; }, // method get_y() { return self.y; } // ]; //}
Examples
We discuss various metaprogram scenarios utilizing basic object-oriented features like encapsulation and information hiding. Such features may differ from what is typically met in the discussion of a metalanguage, but they are chosen on purpose to:(i) emphasize our point that metaprograms are more than atomic macro expressions
(ii) highlight the engineering of stages equally to normal programs using shared state and typical control flow.
We don't argue that such examples cannot be expressed in multi-stage languages that do not offer such facilities, but rather focus on the software engineering advantages gained by adopting the standard programming patterns and techniques practiced in normal programs. In particular, our examples involve grouping common functionality into objects available during compilation and utilizing them to transform multiple source code locations without repeating generation parameters. In a traditional metaprogramming implementation, such examples would have to adopt separate meta-functions, resulting in a procedural paradigm, while their invocations would typically involve repetition of the required parameters, as no state sharing is possible (one should also consider that such parameters are syntactically verbose due to quasi-quotes).
Exception Handling
Exception handling is known to be a global design issue that affects multiple system modules. In this sense, it should be possible to select a specific exception handling policy for the entire system or apply different policies for different components of the system. This can be achieved through metaprogramming: We can use meta-functions to abstract the logic for any exception handling pattern and deploy them to generate the appropriate code at their call sites.
However, without common state across each such invocation is separated from the others and thus requires explicitly repeating all exception pattern details. Moreover, if multiple exception handling patterns are available, it is not possible to parameterize their application to form specific exception handling policies. Using integrated metaprograms, it is possible to maintain a collection of the available exception handling patterns and select the appropriate policy based on configuration parameters or normal control flow while requiring no changes at the call sites inside client code. This is illustrated in the following example.
function Logging (stmts) { return try { stmts; } trap e { log(e); } ; } function ConstructRetry (data) { //constructor for a custom retry policy return function (stmts) { //return a function implementing the code pattern return //the returned function returns an AST for (local i = 0; i < (data.attempts); ++i) try { stmts; break; } //try & break loop when successful trap e { Sleep((data.delay)); } //catch & wait before retrying if (i == (data.attempts)) //maximum attempts were tried? { (data.failure_stmts); } //then give-up & invoke failure code ; }; } Policies = [ //compile-time structure for holding exception policies method Install(key, func) {...}, method Get(key) {...} ]; Policies.Install("LOG", Logging); //install the Logging policy Policies.Install("RETRY", ConstructRetry([ //create and install a retry policy @attempts : 5, @delay : 1000, @fail : post("FAIL") ])); policy = Policies.Get("RETRY"); (policy(f())); //Generates the code below: //for (i = 0; i < 5; ++i) // try { f(); break; } // trap e { Sleep(1000); } //if (i == 5) { post("FAIL"); } policy = Policies.Get("LOG"); (policy(g())); //Generates the code below: //try { g(); } //catch e { log(e); }The Logging policy requires no additional information to be expressed while the Retry policy receives its information (i.e. number of attempts for retrying the operation, the delay to wait between them in case an exception occurs and code to be executed in case all attempts fail) as construction parameters. It is important to note that any parameters are required only once upon construction and are not repeated per policy application. This relieves programmers from repeatedly supplying the required parameters, but more importantly, it achieves a uniform invocation style, allowing different policies to be used interchangeably without changes in their call sites. This means that the single (policy(...)); invocation can generate any of the available exception handling patterns, granted that the policy variable has the corresponding value.
Design by Contract
Design by Contract (DbyC) is a popular method towards self-checking code that improves software reliability. It proposes contracts, constituting computable agreements between clients and suppliers. Clients have to respect method preconditions prior to invocation while suppliers guarantee that the associated postconditions will be satisfied once the invocation completes. Failure to satisfy the promised obligations, on either the client or the supplier side, constitutes a contract violation that will most likely result into an error, typically conveyed as an exception.
In this context, it is possible to use metaprogramming to automatically generate contract verification code. This applies both for the supplier class, whose methods can be enriched with precondition and postcondition checking that raise exceptions upon contract failures, and the class clients, whose invocations can be automatically protected with try-trap blocks. Nevertheless, the definition of the supplier class is separated from the client invocations, meaning that the applications of the code transformations are also typically separated. This means that if the transformation logic is not known a priori, i.e. it relies on some prior compile-time computation, it is not possible to match the generated class definition with a corresponding generation of the class invocations. Even if the transformation logic is predefined, its applications are still separated so they may be applied partly, meaning it is possible to end up with a supplier class that uses DbyC and client invocations that do not or vice versa. In the first case any thrown supplier exception will never be handled by clients, while in the second case client invocations will contain irrelevant exception handling code since the supplier class may not throw any contract exceptions.
This problem can be solved with the state sharing and typical control flow offered by integrated metaprograms. Any transformation to be applied on the supplier class can be stored along with the corresponding transformation required for its usage and be available in the following stage calls that will generate the client invocations, taking into account the transformations performed on the class definition. The following code highlights this functionality, by introducing a single object that can be used to transform both the class definition (through the std::context function discussed earlier) and usages. In particular, the transformer object t contains all relevant transformation information and could be used to handle any number of classes along with their usages. Additionally, notice that the inlining code that uses the transformer object is completely unaware of the actual transformation being applied; this information is properly encapsulated within the transformer object.
function DbyC() { //DbyC transformer return [ //create and return a transformer object method supplier(class) { //generator for the supplier class foreach (local m, class.getMethods()) { //iterate over class methods local pre_id = "pre_" + m.getName();//precondition method id if (class.hasMethod(pre_id)) //does the precondition method exist? m.body.push_front( //add AST at the beginning of the method if (not self[pre_id]()) //has precondition call failed? throw [ //then throw an exception @class : "ContractException", @type : "Precondition", @classId: (class.getName()), @method : (m.getName()) ]; ); //similar logic to add postcondition checking code at the method end here } return nil; //no additional code to be inlined in the supplier context }, method client(invocation_stmts) { //generator for the client invocations return try { invocation_stmts; } trap ContractException { log(ContractException); } ; } ]; } t = DbyC(); //compile-time transformer object function Stack() { return [ method empty {...}, //Pop is transformed as follows: method pre_pop{...}, //method pop { method pop {...}, // if (not self["pre_pop"]()) // throw [ ( t.supplier( // @class : "ContractException", std::context("class") // @type : "Precondition", )); // @classId: "Stack", // @method : "pop" ]; // ]; } // ...original body of pop method here //} st = Stack(); (t.client(st.pop())); //Generates the code below: //try { st.pop(); } //trap ContractException { log(ContractException); }Design patterns
Design patterns constitute generic reusable solutions to commonly recurring problems within a given context in software design. Effective software design requires considering issues that may not become visible until later in the implementation and design patterns can help preventing such problems by providing tested, proven development paradigms. A design pattern is not a complete design directly transformable into code; it is rather a description on how to solve the given problem in different situations illustrating relationships and interactions between classes and objects involved. This means that in general, a pattern has to be re-implemented from scratch each time it is used, thus significantly reducing the achieved reusability.
Towards this direction, it is possible to utilize metaprogramming to support generating concrete pattern implementations. The pattern application logic can be expressed as a metaprogram, the concepts of the pattern can be incorporated as functionality or state present within the metaprogram, while any information depending on a particular application context can be considered as deployment parameters. However, such metaprograms may require elaborate programming practices not applicable in a typical metalanguage.
In integrated metaprograms, programmers can apply any typical programming practices like encapsulation, abstraction and separation of concerns, thus significantly improving the development process. For example, it is possible to abstract the pattern implementation logic into object-oriented code generator objects. Additionally, it is possible to have multiple such code generators available (or even hierarchies of code generators) and being able to select the appropriate one at compile-time based on the application context without affecting the invocation style used in their deployment. This functionality is demonstrated in the following example that implements the adapter pattern. The pattern is implemented in two ways, using delegation and sub-classing, while its application may be parameterized at compile-time.
function GetClassDef (target) {...} //uses compiler state to find the target class function AdapterByDelegation() { //creates an adapter object that uses delegation return [ method adapt (spec) { local methods = nil; //AST of adapted class methods, initially empty local class = GetClassDef(spec.original); foreach(local m, class.getMethods()) { //iterate over class methods local name = m.GetName(); local newName = spec.renames[name]; if (not newName) newName = name; //if no renaming use original name methods = //merge existing adapted methods with the current one methods, method newName (...) { @instance.name(...); } ; } return //create and return the adapted class using the adapted methods AST function (spec.adapted) (...) { return [ @instance : (spec.original)(...), methods ]; } ; } ]; } function AdapterBySubclassing() { //creates an adapter object that uses subclassing return [ method adapt (spec) { local adaptedMethods = nil; //AST of methods to be adapted local class = GetClassDef(spec.original); foreach(local m, class.getMethods()) { //iterate over class methods local name = m.GetName(); local newName = spec.renames[name]; if (newName) //only check renamed methods, other are inherited by base class adaptedMethods = //merge adapted methods with the current one adaptedMethods, method newName (...) { self.name(...); } ; } return //the adapted class as a subclass that introduces the adapted methods function (spec.adapted)(...) { local base = (spec.original)(...); //base class object local derived = [adaptedMethods]; //derived class object std::inherit(derived, base); //derived object inherits from base return derived; } ; } ]; } AdapterFactory = [ //Creating and populating a factory with adapter implementations method Install (type, func) { self[type] = func; }, method New (type) { return self[type](); } ]; AdapterFactory.Install("delegation", AdapterByDelegation); AdapterFactory.Install("subclassing", AdapterBySubclassing); adapterType = "delegation"; //can also be read or computed dynamically adapter = AdapterFactory.New(adapterType); //create an adaptor object function Window(args) { return [ method Draw() {...}, method SetWholeScreen() {...}, method Iconify() {...} ]; } windowAdapterData = [ //compile-time data for the window adapter @original: Window, @adapted : WindowAdapter, @renames : [ { "SetWholeScreen" : "Maximize" }, { "Iconify" : "Minimize" } ] ]; (adapter.adapt(windowAdapterData)); //Generates the code shown below: //function WindowAdapter(...) { // return [ // @instance : Window(...), // method Draw(...) { @instance.Draw(...); }, // method Maximize(...) { @instance.SetWholeScreen (...); }, // method Minimize(...) { @instance.Iconify(...); } // ]; //} adapter = AdapterFactory.New("subclassing"); windowAdapterData.adapted = WindowAdapter2; (adapter.adapt(windowAdapterData)); //Generates the code shown below: //function WindowAdapter2(...) { // local base = Window(...); // local derived = [ // method Maximize(...) { self.SetWholeScreen(...); }, // method Minimize(...) { self.Iconify(...); } // ]; // std::inherit(derived, base); // return derived; //}Such code generator objects can also abstract implementation details of the classes they generate. This means that such details may be specified only once upon creation and never repeated at each use site. For instance consider a Singleton class that may adopt different invocation styles (e.g. static functions or static instance and methods), that may even be declared within a namespace, thus requiring extra syntax in its usage. Implementing such a code generation scheme in a typical language would require repeating the generated class details at every inline site something both tiresome (consider that such details are syntactically verbose due to quasi-quotes) and error-prone. Similarly, updating or replacing such implementation details (e.g. for refactoring purposes) would require manually locating the affected code fragments and applying the proper changes for any of them. Below we show an example of abstracting the implementation details for the definition and usages of a MemoryManager singleton class. In this example, the singleton class is modeled either through a prototype function or as global data.
memoryManagerClass = //basic MemoryManager class implementation [ method Initialize () {...}, method Cleanup () {...}, method Allocate (n) {...}, method Deallocate (var) {...} ] ; function GenerateMemoryManagerAsFunction() { return [ @defs : function MemoryManager() { if (not static mm) //static initialization idiom mm = memoryManagerClass; return mm; } , @init : MemoryManager().Initialize(), @cleanup : MemoryManager().Cleanup(), method alloc(n) { return MemoryManager().Allocate(n) ; }, method dealloc(var) { return MemoryManager().Deallocate(var) ;} ]; } function GenerateMemoryManagerAsGlobalData(){ return [ @defs : mm = memoryManagerClass , @init : mm.Initialize(), @cleanup : mm.Cleanup(), method alloc (n) { return mm.Allocate(n); }, method dealloc (var) { return mm.Deallocate(var); } ]; } memoryManagerImplementations = [ @func : GenerateMemoryManagerAsFunction, @global: GenerateMemoryManagerAsGlobalData ]; option = "global"; //can also be read or computed dynamically mm = memoryManagerImplementations[option](); //get the generator object (mm.defs); //Generates the code shown below: //mm = [ // method Initialize () {...}, // method Cleanup () {...}, // method Allocate (n) {...}, // method Deallocate (var) {...} //]; //...other normal program definitions... (mm.init); //mm.Initialize(); //...other normal program initializations... x = (mm.alloc(10)); //x = mm.Allocate(10); //...other normal program code... (mm.dealloc(x)); //mm.Deallocate(x); //...other normal program cleanups... (mm.cleanup); //mm.Cleanup();As shown, the invocation details are specified only once for each case and are abstracted through the mm code generator object, allowing matching definition and usage pairs to be automatically produced without requiring any additional information. The latter allows updating the generation parameters, possibly affecting names or calling styles, however, without having to change anything regarding the use of the generated class.
Staged Model-Driven Generators
Generative model-driven engineering (MDE) tools rely on modeling the entities of a system and then using code generators to automatically produce source code for their implementation. The generated model code can be extended or linked with custom application code to deliver the final application. The practice of extending the automatically generated code involves maintenance issues as any manually introduced code will be overwritten once the model code is regenerated.
These maintenance issues can be addressed by adopting metaprogramming practices for combining model code and custom application code as follows. The outcome of the MDE tool should be produced not as editable source files but as read-only ASTs. Then a metaprogram can load these ASTs, combine them with custom application functionality or maybe with ASTs produced by other MDE tools and finally insert the result directly in the source being compiled. In this sense, the application directly deploys and manipulates generated code fragments instead of being built around them.
The following code demonstrates the improved MDE process by loading, combining and generating the model code for a paint application. In particular, the user interface is derived by two models (a general paint interface and an additional toolbar for shapes), while there is an additional model for a class hierarchy used in the application (shapes like circles, rectangles, etc. implementing the shape toolbar functionality). The models are assumed to be already created by third party modeling tools and their corresponding source code has been stored as binary AST files (through custom code generators).
using wx; //normal code, directive for importing the wxWidgets GUI toolkit paintUI = load_ast("paint.ast"); //load the AST of the paint application user-interface code shapesUI = load_ast("shapes.ast"); //load the AST of the shapes toolbar user-interface code classes = load_ast("classes.ast"); //load the AST of the class hierarchy for the toolset function MergeGUI(main, toolbar){...} //compile-time function to integrate an interface containing MergeGUI(paintUI, shapesUI); //a toolbar UI to the main program UI classes.Geometry.Circle.draw.body = //insert custom implementation for method Circle::draw(dc) dc.drawcircle(@center, @radius);; //dc: argument, @center and @radius: circle attributes //other shape method implementations //custom functionality and event handling code inserted here as well //any other meta-code or normal code may be freely inserted before, between or after the inline directives (classes); //inline the transformed classes AST at this source location (paintUI); //inline the transformed paintUI AST at this source location - this generates function CreateGUI wx::app_start(CreateGUI); //normal code, uses the generated CreateGUI function to launch the GUIThe complete source code for the above example, as well as additional case studies regarding model-driven staged generators are available from here, while a video demonstrating the entire MDE process is provided below.
Information
Credits
The Delta language, its Sparrow IDE, and all accompanying tools or libraries, have been developed at the Institute of Computer Science, FORTH.The Delta language is designed, developed, extended and maintained by Anthony Savidis (2004-present) . The latter includes the compiler, virtual machine, standard library, debugger backend / frontend and the Disco console debugger. He is also the chief architect and development supervisor of all implementation activities related to the Delta language.
Yannis Georgalis and Themistoklis Bourdenas co-developed the initial version of the Sparrow IDE as part of their Masters work (2006-2007) .
Yannis Lilis: (i) enhanced the project manager and debugger user-interface of the Sparrow IDE, while he fixed numerous bugs of the initial version (2007) ; (ii) implemented in the Delta language an extension component of the Sparrow IDE to support tree views for expression watches (2008) ; (iii) implemented the linkage with Corba, enabling build Corba clients or servers directly in the Delta language (2009) ; and (iv) implemented the metaprogramming extensions for the Delta language and all related metaprogramming and aspect-oriented programming extensions and facilities of the Sparrow IDE (compile-time debugging, debugging of aspect programs, AST inspection, etc.) as part of his PhD work (2010-2013) .
Nikos Koutsopoulos implemented: (i) the search and replace facility of the editor as part of his Diploma work (2009) ; and (ii) the i-views component (interactive object graph for the source-level debugger) as part of his Masters work (2009-2011) .
Andreas Maragudakis implemented: (i) a parser which loads XML files into Delta objects as part of his Diploma work (2009) ; and (ii) the porting of wxWidgets as a dynamically-loaded Delta library (2010) .
Irini Papakwnstantinou implemented in the Delta language the source browser of the Sparrow IDE (an extension component) as part of her Diploma work (2009) .
Kostantinos Mousikos implemented in the Delta language a generator of interactive web documents as part of his Diploma work. The latter has been used to produce the (entire) current site (2009) .
Christos Despotakis implemented in the Delta language the build tree view of the Sparrow IDE (an extension component) as part of his pre-Diploma work (2010) .
Yannis Apostolidis as part of his Diploma work implemented: (i) a parser which loads JSON files into Delta objects; and (ii) an encoder of aggregates to JSON for the Delta debugger backend (2013) .
Giorgos Koutsouroumpis as part of his Diploma work has implemented the build dependecies visualizer in the Delta language (2013) .
Giorgos Diakostavrianos as part of his Diploma work has significantly improved the performance of the Delta build system in the Sparrow IDE by supporting (cached) build logs (2014) .
Site development, maintainence and contact person: Anthony Savidis
Download
You can download the installer of the Sparrow IDE from here (Windows executable only, tested on Windows XP SP2 or greater, Windows Vista, Windows 7). You may also gain the current version of the source code (Visual Studio 2005, 2010 and 2013 Solutions), for non-commercial purposes only , through our Subversion server, using a checkout command from a console as follows (please consider that the checkout operation may take a few minutes due to the various binary files included in the distribution, besides the source code files):svn co https://139.91.186.186/svn/sparrow/trunk --username guest
Alternatively you may use your own ghraphical svn client to checkout from repository https://139.91.186.186/svn/sparrow/trunk supplying as user name 'guest' and an empty password. When checkout completes, you neeed to carry out the following steps to build the Sparrow IDE:
1) Install either Visual Studio 2005 (with SP1), 2010 (with SP1) or 2013 (with update 3)
2) Install the external libraries dependencies by obtaining prebuilt versions or manually building them from source. The libraries required are (we tested only for these, but it should work on other versions too):
Boost versions 1.34 or 1.45 - 1.47 or 1.56,
wxWidgets versions 2.8.3 or 2.8.11 - 2.8.12 or 2.9.4 - 2.9.5 or 3.0.0 - 3.0.1
2.1) If manually building the libraries from source:
2.1.1) Copy all dlls (both debug and release mode) at trunk/Build
2.1.2) Create DELTAIDEDEPS environmant variable with value the full path of a ThirdPartyLibraries folder as shown in the image below (you may choose a different folder name but should adopt the same folder structure).
2.1.3) Create WXWINDIR environmant variable with value the full path of the ThirdPartyLibraries\wxwidgets folder as shown in the image below (you may choose a different folder name but should adopt the same folder structure).
2.1.4) Create WXWINVER environmant variable with a value specifying the wxWidgets version as follows: WXWIN28 for versions 2.8.*, WXWIN29 for versions 2.9.*, and WXWIN30 for versions 3.0.*
|
|
|
*** Folder structure for Sparrow third-party libraries *** |
2.2) If using prebuilt libraries:
2.2.1) If you have Visual Studio 2013 (with update 3):
2.2.1.1) Install the prebuilt external library dependencies directly from here (includes Boost 1.56 and wxWidgets 3.0.1)
2.2.1.2) When installed, the DELTAIDEDEPS , WXWINDIR and WXWINVER environment variable are automatically set
2.2.1.3) Extract wxwidgets runtime dlls from $DELTAIDEDEPS/bin/wx-runtime-dlls-3.0.1-vc12update3.rar at trunk/Build
2.2.2) If you have Visual Studio 2010 (with SP1):
2.2.2.1) Install the prebuilt external library dependencies directly from here (includes Boost 1.47 and wxWidgets 2.8.12)
2.2.2.2) When installed, the DELTAIDEDEPS environment variable is automatically set (along with a WXWIN28 variable used later)
2.2.2.3) Extract wxwidgets runtime dlls from $DELTAIDEDEPS/bin/wx-runtime-dlls-2.8.12-vc10sp1.rar at trunk/Build
2.2.2.4) Run (as administrator) trunk/Build/Installer/update.bat to generate the WXWINDIR and WXWINVER environment variables (this uses the previously set WXWIN28 variable)
2.2.3) If you have Visual Studio 2005 (with SP1):
2.2.3.1) Install the prebuilt external library dependencies directly from here (includes Boost 1.34 and wxWidgets 2.8.3)
2.2.3.2) When installed, the DELTAIDEDEPS environment variable is automatically set (along with a WXWIN28 variable used later)
2.2.3.3) Extract wxwidgets runtime dlls from trunk/Build/wx-runtime-dlls-2.8.3.rar at trunk/Build
2.2.3.4) Run (as administrator) trunk/Build/Installer/update.bat to generate the WXWINDIR and WXWINVER environment variables (this uses the previously set WXWIN28 variable)
3) Run (as administrator) trunk/Build/Installer/install.bat to generate a DELTA environment variable and properly associate Sparrow configuration files
4) Open the Visual Studio solution from trunk/IDE/
4.1) For Visual Studio 2005 open IDE2005.sln
4.2) For Visual Studio 2010 or 2013 open IDE.sln
5) Unload Tools/Delta/Extra/CORBA folder (it requires TAO CORBA source distribution)
6) Build all
7) To run Sparrow from Visual Studio you should set Application as the startup project
8) Optionally run trunk/Build/registry.bat to associate .wsp files to open with Sparrow
9) Bootstrapping process:
9.1) Run Sparrow and discard any error messages encountered
9.2) The last message will ask to open the Sparrow workspace to resolve errors. Select Yes.
9.3) Build the newly opened workspace
9.4) From the Adaptations component, right-click on the desired profile (e.g. Sparrow Devel) and Select it to apply changes
9.5) Sparrow should now be up and running
Also, after svn checkout, a folder structure will be created under a directory named 'trunk', containing the implementation sources of the Sparrow IDE and the Delta language. Below we indicate the actual path to the Delta language implementation folders.
|
|
|
*** Spotting the Delta language folders in the svn folder hierarchy *** |
Additionally, within the 'Sparrow/trunk/IDE' directory you will find the 'IDE.sln' and 'IDE2010.sln' files, being respectively Visual Studio 2005 and 2010 solution files for the entire language distribution (including the Delta language components and the IDE istelf). Once opened, they display the solution hierarchy outlined below, where we spot the path to the Delta language components.
|
|
|
*** Spotting the Delta language componets in the solution hierarchy *** |

Publications
Below is a list of publications related to the Delta language and the Sparrow IDE:-
Lilis, Y., Savidis, A. (2014)
An Integrated Implementation Framework for Compile-Time Metaprogramming.
Softw: Pract. Exper. To appear.
doi:
10.1002/spe.2241
-
Lilis, Y., Savidis, A. (2014)
Aspects for Stages: Cross Cutting Concerns for Metaprograms.
Journal of Object Technology. To appear.
-
Lilis, Y., Savidis, A. (2013).
An Integrated Approach to Source Level Debugging and Compile Error Reporting in Metaprograms.
Journal of Object Technology 12(3): 1: 1-26.
doi:
10.5381/jot.2013.12.3.a2
-
Lilis, Y., Savidis, A., Valsamakis, Y. (2014)
Staged Model-Driven Generators: Shifting Responsibility for Code Emission to Embedded Metaprograms.
In Proceedings of the 2nd International Conference on Model-Driven Engineering and Software Development (MODELSWARD 2014), 7-9 January, Lisbon, Portugal.
-
Savidis, A., Koutsopoulos, N. (2014).
A Programmer-Centric and Task-Optimized Object Graph Visualizer for Debuggers.
In M. Huang and W. Huang (ed.) Innovative Approaches of Data Visualization and Visual Analytics, 1st Edition, IGI Global, pp. 385-396.
doi:
10.4018/978-1-4666-4309-3.ch018
-
Lilis, Y., Savidis, A., Valsamakis, Y. (2013).
Self Model-Driven Engineering Through Metaprograms.
In Proceedings of the 17th Panhellenic Conference on Informatics (PCI 2013), 19-21 September. ACM, New York, NY, USA, 136-143.
doi:
10.1145/2491845.2491872
-
Lilis, Y., Savidis, A. (2012).
Implementing Reusable Exception Handling Patterns with Compile-Time Metaprogramming.
In SERENE 2012 4th International Workshop on Software Engineering for Resilient Systems, Pisa, Italy (September 27-28), Springer LNCS 7527, 1-15.
doi:
10.1007/978-3-642-33176-3_1
-
Lilis, Y., Savidis, A. (2012).
Supporting Compile-Time Debugging and Precise Error Reporting in Meta-Programs.
In TOOLS 2012, International Conference on Objects, Models, Components, Patterns (29-31 May), Prague, Czech Republic, Springer LNCS 7304, pp 155-170.
doi:
10.1007/978-3-642-30561-0_12
-
Savidis, A., Koutsopoulos, N. (2011).
Interactive object graphs for debuggers with improved visualization, inspection and
configuration features.
In Proceedings of the 7th international conference on Advances in visual computing - Volume Part I (ISVC'11),
George Bebis, Richard Boyle, Bahram Parvin, Darko Koracin, and Song Wang (Eds.), Vol. Part I. Springer-Verlag, Berlin, Heidelberg, 259-268.
doi:
10.1007/978-3-642-24028-7_24
-
Savidis, A. (2011).
Integrated implementation of dynamic untyped object-based operator overloading.
Softw: Pract. Exper., 41: 1155-1184.
doi:
10.1002/spe.1025
-
Savidis, A. (2011).
Supporting cross-language exception handling when extending applications with embedded languages.
In Proceedings of the Third international conference on Software engineering for resilient systems (SERENE'11), Elena A. Troubitsyna (Ed.). Springer-Verlag, Berlin, Heidelberg, 93-99.
doi:
10.1007/978-3-642-24124-6_8
-
Savidis, A., Lilis, Y. (2009).
Support for language independent browsing of aggregate values by debugger backends.
Journal of Object Technology, Volume 8, no. 6 (September 2009), pp. 159-180.
doi:
10.5381/jot.2009.8.6.a4
-
Savidis, A., (2008).
An enhanced form of dynamic untyped object-based inheritance.
Journal of Object Technology, Volume 7, no. 4 (May 2008), pp. 101-122.
doi:
10.5381/jot.2008.7.4.a2
-
Savidis, A., Bourdenas, T., Georgalis, J. (2007).
An Adaptable Circular Meta-IDE for a Dynamic Programming Language.
In the Proceedings of the 4th international workshop on Rapid Integration of Software Engineering Techniques (RISE 2007) (pp. 99-114), 26-27 November 2007, Luxemburg.
Online PDF
-
Savidis, A. (2006).
An Informal Proof on the Contradictory Role of Finalizers in a Garbage Collection Context.
FORTH-ICS / TR381.
2006.TR381_Finalizers_and_Garbage_Collection.pdf
-
Savidis, A. (2005).
More dynamic imperative languages.
SIGPLAN Not. 40, 12 (December 2005), 6-13.
doi:
10.1145/1117303.1117305
-
Savidis, A. (2005).
Dynamic Imperative Languages for Runtime Extensible Semantics and Polymorphic Meta-Programming.
In proceedings of RISE 2005, International Workshop on Rapid Integration of Software Engineering Techniques (RISE 2005). Heraklion,
Crete, Greece, 8-9 September 2005 (pp. 113-128). Berlin Heidelberg: Springer-Verlag (LNCS 3943).
doi:
10.1007/11751113_9
-
Savidis, A. (2005).
The Delta Dynamic Object-Oriented Programming Language.
FORTH-ICS / TR 358.
2005.TR358_Delta_Dynamic_Object-Oriented_Programming_Language.pdf
Standard library
Constants
To check against the result of typeof(): TYPEOF_NUMBER TYPEOF_STRING TYPEOF_TABLE TYPEOF_OBJECT TYPEOF_PROGRAMFUNC TYPEOF_LIBRARYFUNC TYPEOF_BOOL TYPEOF_EXTERNID TYPEOF_NIL TYPEOF_METHODFUNC TYPEOF_UNDEFINED To use while processing the results of vmextractbuilddeps(): DEPENDENCY_NOT_FOUND DEPENDENCY_ONE_FOUND DEPENDENCY_MANY_FOUND To check the designated superclass of an object or externid like 'a[std::ALGORITHMS_SUPERCLASS] == std::ALGORITHMS_ITERATOR' ALGORITHMS_SUPERCLASS ALGORITHMS_ITERATOR ALGORITHMS_CONTAINER Values to the optional PacketWrapping parameter for sockets: SOCKET_PACKET_ORIGINAL SOCKET_PACKET_ADD_SIZE
Mischellaneous
print(v1,...,vn) Output (default is console).
Value callglobal(String,[args]) Calls a function at program scope by name
String typeof(Value) Returns one of the following:
'Number'
'String'
'Table'
'Object'
'ProgramFunc'
'LibraryFunc'
'Bool'
'ExternId'
'Nil'
'MethodFunc'
'Undefined'
bool iscallable(x) Returns true if a function or a functor.
bool isnil(value)
bool isundefined(Value)
String externidtype(ExternId) Returns user-defined extra type for extern ids
Proto externiduserdata(ExternId) Returns standard supported user data for extern ids
Value taggedvalue(val, String) Returns a value with a tag, also passed on assignment (put empty string to remove tag).
String getvaluetag(val) Returns the type tag of a value (default is empty string).
Bool isoverloadableoperator(val) Should be used with dot overloading to identify when an opertator is requested
bool equal(x,y) Equality test, ignoring overloading (useful among objects / externids)
Number currenttime()
String getenvironmentvar (String(id)) Returns value of an environment var (Nil if not found)
error(String) Causes an error at the calling VM
String tostring(Value) Conversion to string, respects overloading
File I/O
After creation can use functions with an OO syntax (obj.method) without the prefix 'file' (for those functions accepting fp as an argument). Normally, you will use the filewrite and fileread functions for very simply needs, as in most cases you will deploy the function set for readers / writers and binary I/O buffers. ExternId fileopen(path, mode) mode is any of 'rt', 'wt', 'at', 'rb', 'wb', 'ab' fileclose(fp) fileremove(path) filewrite(fp, x1, ..., xn) Textual write Value fileread(fp, type) Textual read, type is any of 'string', 'number', 'bool' String filegetline(fp) Reads next text line from file Bool fileend(fp) String filetmpname() fileexecute(String(cmmd)) OS shell command execution
Global operator overloading
Those functions overload globally (their operator functions are called when everything else fails in operator resolution). setarithmeticoperator (op, callable) setrelationaloperator (op, callable) setassignmentoperator (callable) settypecastingoperator(callable) Value getarithmeticoperator (op) Value getrelationaloperator (op) Value getassignmentoperator () Value gettypecastingoperator ()
Library function manipulation
LibFunc libfuncget(String) Get a lib func by name at runtime Bool libfuncisbound(f) Returns if a library func was bound with args LibFunc libfuncbind(f, [args]) Returns a lib func binding args to f; if f was bound, its args are copied first. LibFunc libfuncunbound(f) Retuns a lib func for f with no bound args. List / Nil libfuncgetboundargs(f) Returns bounds args list (reference) or nil (if no bound args); editing the list is editing the bound args of 'f' lib function.
Resource loader
Object rcload(String(path)) Loads config data. rcsetpreprocessor( Sets preprocessor use. String(cpp), Full exe path; pass empty string to disable preprocessing phase. String(includeFlags) Include flags; pass empty string when 'cpp' arg is empty too. ) Table rcparse(String(text)) Loads from a text string String rcloadgeterror() Get error if parsing failed Bool rcstore(t, path) Store a table in rc format
Objects
Value tabget(t, i) Local, unoverloaded tabset(t, i, c) Local, unoverloaded tabnewattribute(t, id, set, get) Adds a new attribute entry tabredefineattribute(t,id,set,get) Changes set / get of an already existing attribute tabsetattribute(t,id,content) Sets locally the internal attribute slot (unoverloaded access) Value tabgetattribute(t,id) Gets locally the internal attribute slot (unoverloaded access) Number tablength(t) Table tabindices(t) Returns indices of a table as a new table with numeric indices Table tabcopy(t) Shallow copy tabclear(t) Clears locally (no effect on inheritance stuff) tabenableoverloading(t) Enables overloading (default is always enabled) tabdisableoverloading(t) Disables overloading Bool tabisoverloadingenabled(t) Returns true if overloading is enabled. tabsetmethod(t1, t2, i, j) (requires t2[j] method) t1[i] = t2[j], t1[i].owner = t1 tabextend(src, dest) Copies fields of src to dest, setting also method ownership to dest Method tabmethodonme(t,m) Returns a method value like m, but with self now set to t. ExternId tabserialise(t) Returns an output buffer (keeps only bool, number, string and object values). Table tabdeserialise(inputbuffer(ib)) Deserialises from an input buffer (nil if serialisaiton failed). Iter tableiter_new() Iter tableiter_setbegin(i,t) Iter tableiter_setend(i,t) tableiter_checkend(i,t) tableiter_checkbegin(i,t) tableiter_equal(i,j) tableiter_assign(i,j) Iter tableiter_copy(i) Iter tableiter_fwd(i) Number tableiter_getcounter(i) Counter of current iteration element Table tableiter_getcontainer(i) Value tableiter_getval(i) Get value at current position tableiter_setval(i,v) Change value at current position (r/w access allowed) Value tableiter_getindex(i) Get index of current position (no setindex is provided)FUNCS_END
Dynamic linked libraries
ExternId dllimport (String(path), String(func)) May install lib funcs, load and run scripts upon initialisation. ExternId dllimportdeltalib (String(path), String(func)) Same as before, but func is internally extended to 'Instal_Delta' + <func> +'_Lib' dllimportaddpath (path:String) Adds a path to resolve dll files in all dllimport functions Result dllinvoke (ExternId(dll), String(func)) Result type is [{.succeeded: <Boolean>}, {.value: <String> } ] Bool dllhasfunction ExternId(dll), String(func)) Returns true if function 'func' exists in the dll. dllunimport (ExternId(dll)) dllunimportdeltalib (ExternId(dll)) Same as before, but also calls an 'CleanUp' function before unloading
Inheritance (subobject trees)
inherit(derived, base) Added as left-most parent (more recent)
inheritredirect(derived, base) Cancels base's old derived if any and performs normal inherit
uninherit(derived, base)
bool isderived(derived, base)
Table getbases(obj) Numerically indexed [0,..N-1], i < j => i most recent base than j
Proto getbase(obj, i) Equivalent to getbases(obj)[i], but way more fast.
Proto getderived(obj) The single child
Proto getmostderived(obj) The most derived in the tree
Delegation
delegate(from, to)
undelegate(from, to)
Bool isdelegate(from, to) If there is a delegation path from --> to
Bool isdirectdelegate(from, to) If there is a delegation link from -> to
Bool isdelegator(to, from) Returns if isdirectdelegate(from, to)
Table getdelegates(obj) Returns all direct delegates
Table getdelegators(obj) Returns all y such that isdelegator(obj,y), or,
equivalently, isdirectdelegate(y, obj)
Binary I/O buffers
After creation can use functions with an OO syntax (obj.method) without the prefixes 'inputbuffer_' and 'outputbuffer_' Next is garbage collectable: ExternId inputbuffer_new(ExternId(ob)) Makes an input buffer from an output buffer 'ob' inputbuffer_set(ib, ob) Sets again an existing input buffer 'ib' from output buffer 'ob' inputbuffer_rewind(ib) Repositions at start Number inputbuffer_size(ib) Total size in bytes Number inputbuffer_remaining(ib) Total remaining bytes to be read Bool inputbuffer_eof(ib) If at end of buffer Next is garbage collectable: ExternId outputbuffer_new() Makes a new empty output bufefr outputbuffer_append(dest, src) Append to 'dest' output buffer the 'src' (copied) Bool outputbuffer_isempty(ob) If nothing written yet Number outputbuffer_size(ob) Total bytes written on output buffer Number outputbuffer_totalpackets(ob) Total number of separate write operations over 'ob' outputbuffer_clear(ob) Clears everything written to 'ob' outputbuffer_flush(ob, fp) Flushes to a file (does not affect 'ob')
Binary readers / writers
After creation can use functions with an OO syntax (obj.method) without the prefixes 'reader_' and 'writer_' Next is garbage collectable: ExternId reader_fromfile(fp) Makes a bin reader from a file pointer ExternId reader_frominputbuffer(ib) Makes a bin reader from an input buffer Number reader_read_ui8(r) Number reader_read_ui16(r) Number reader_read_i16(r) Number reader_read_ui32(r) Number reader_read_i32(r) Number reader_read_bool8(r) Number reader_read_real64(r) String reader_read_string(r) InputBuffer reader_read_buffer(r, size) Next is garbage collectable: ExternId writer_fromfile(fp) Makes a bin reader from a file pointer ExternId writer_fromoutputbuffer(ob) Makes a bin reader from an output buffer writer_write_ui8(w, Number) writer_write_ui16(w, Number) writer_write_i16(w, Number) writer_write_ui32(w, Number) writer_write_i32(w, Number) writer_write_bool8(w, Number) writer_write_real64(w, Number) writer_write_string(w, String) writer_write_buffer(w, ob) An output buffer is supplied.
Sockets
After creation can use functions with an OO syntax (obj.method) without the prefix 'socket_' ExternId socket_createforclient() Produces a client socket socket_createforserver(Number(port)) Produces a server socket socket_destroy(socket) Destroyes a socket (and closes connection) socket_connecttoserver( Connects to a server (check with socket_isconnectionbroken if ok) clientsocket, String(address), Number(port), Number(timeout) // if 0, one try is only performed ) ExternId socket_acceptclient( Accepts a client (if failed returns Nil) serversocket, Bool(blocking), // will block until connected Number(timeout) // only if non-blocking is used ) Bool socket_isconnectionbroken(socket) PacketWrapping below can be either: std::SOCKET_PACKET_ORIGINAL // users packets as they are std::SOCKET_PACKET_ADD_SIZE // size (unsigned long, net byte ordering) preceeds user packets Bool socket_ismessagepending( socket [, String(PacketWrapping) = SOCKET_PACKET_ADD_SIZE] ) socket_waitanymessage( socket, Number(timeout) // if timeout is 0 we wait forever until a message is received [, String(PacketWrapping) = SOCKET_PACKET_ADD_SIZE] ) InputBuffer socket_receive( Receives incoming data as an input buffer (if no message returns nil) socket [, String(PacketWrapping)] ) InputBuffer socket_blockreceive( Blocking receipt of incoming data as an input buffer socket [, String(PacketWrapping) = SOCKET_PACKET_ADD_SIZE] ) socket_send( Sends data from an output buffer socket, ExternId(outputbuffer) [, String(PacketWrapping) = SOCKET_PACKET_ADD_SIZE] )
Strings
Number strlen(s) String strslice(s, l1,r1,l2,r2,...,ln,rn) Returns: s[l1]+...+s[r1] +...+ s[ln]+...+s[rn]. Requires: li <= ri, 0 <= li or ri <= strlen(s)-1. Special case: if ri is 0, then ri assumed strlen(s)-1. Number strsub(s1,s2) Returns index of first occurence of s2 in s1, else -1 String strlower(s) String strupper(s) Number strbyte(s, Number(i)) s[i] character ASCII value String strchar(s, Number(i)) s[i] character as a string value String strbytestr(Number(c)) c ASCII value to String Bool strisalpha(Number(i)) Tests an ASCII code (alpha) Bool strisalnum(Number(i)) Tests an ASCII code (alphanumeric) Bool strisdigit(Number(i)) Tests an ASCII code (decimal digit) Bool strisspace(Number(i)) Tests an ASCII code (white space) Bool strisprint(Number(i)) Tests an ASCII code (printable at console ) Bool strislower(Number(i)) Tests an ASCII code (lowercase letter) Bool strisupper(Number(i)) Tests an ASCII code (uppercase letter) Bool strisident(s) Returns true if s is a legal Delta identifier Bool strisprefix(s, s_prefix) Returns true if s_prefix is a prefix of s String strrep(s,n) s+...+s n times Number strtonum(String) String list strtokenise( Tokenizes a string 's' to a sequence of strings NEW s:String, using character tokens from 'tokens' tokens:String ) Bool strsavetofile( Overwrites file at 'path' as a new text file with content from 'text' String(text), String(path) )
Shared memory
This is actually in-process, but cross-vm shared memory enabling to interoperate intuitively among different scripts (vms at runtime). Bool shexists(String id) shwrite(id, val) Value shread(id) shdelete(id) Table shobject() Internal shared object returned, that is the same for all vms.
Bit operators
Number bitand(Number x, Number y) Number bitor(x, y) Number bitnot(x) Number bitxor(x, y) Number bitshright(x, n) Number bitshleft(x, n)
Math functions
Number sqr(x) Number sqrt(x) Number cos(theta) theta in degrees Number sin(theta) Number tan(theta) Number abs(x) Number max(x1,...,xn) Number min(x1,...,xn) Number random(n) In 0,...,n-1 Number randomise() Number power(x, exp) x ^ exp Number pi() Number fractionalpart(x) Number integerpart (x)
Virtual machine management
VM vmget(id) Table vmfuncs(vm / id) Get all globals funcs in a table indexed with their names. Value vmcall(vm / id, String(func)[, arg1,...,arg-n]) String vmid(vm) Func vmfuncaddr(vm / id, String(func)) VM vmthis() VM vmload(String(srcPath), String(unique id)) vmloadaddpath (path:String) Adds a loading path used by all functions loading bytecode into vms VM vmloadfrominputbuffer(ExternId(ib), String(unique id)) VM vmloadfromreader(ExternId(reader), String(unique id)) vmrun(VM) vmunload(VM) VM vmof(Function or Method) If was unloaded, it returns nil Bool vmisvalid(VM) Returns if the VM is alive vmseterrorinvalidatesall(Bool) Bool vmhaserror(VM) vmreseterror(VM) Cannot be called from code of the erroneous VM Bool vmhaserrorsomewhere() If there is a VM which produced an error vmresetallerrors() Reset errors in all vms String vmgeterrorreport() Table vmcurrcall() Returns information on the present call as a tuple: [ tag: <number>, func: <function value or undef if in global code>, name: <function name or 'at global code'> vm: <the vm in which the call is made> ] Table vmnextcall(Number(callTag)) Returns the next call of the call whose tag is supplied. If the current call is the bottom call, Nil is return instead. Normally you make t = vmcurrcal(); t = vmnextcall(t.tag); String vmgetstacktrace() Returns the stack trace as a string (includes new lines).FUNCS_END Also, the following functions may be called as methods using a VM 'x', without the prefix 'vm', and without passing the vm as a parameter. x.call(String(func)[, arg1,...,arg-n]) same as vmcall(x, String(func)[, arg1,...,arg-n]) x.funcs x.funcaddr x.run x.haserror
Bytecode libraries
The following library functions belong to the nested namespace 'libs' within 'std' namespace. They allow treat compiled binaries (byte code) as libraries with a logical identifier, once initially registered using the 'register' function-set below. When an 'import' call is made, a distinct vm instance is produced for non-shared libraries, that is also directly run. For shared libraries this is done only once upon the first 'import' invocation. The vms created this way may be explicitly released using 'unimport' function. This works fine for shared libraries too (they are released with a reference counter). Also, vms are protected depending on the way the are created, so it is illegal to 'vmunload' vms made with 'import' and to 'unimport' vms made with 'vmload' (you will get a runtime error if you do this). libs::registercopied (String(id), String(byte code path)) libs::registercopied (String(id), inputbuffer (byte code stream)) libs::registershared (String(id), String(byte code path)) libs::registershared (String(id), inputbuffer (byte code stream)) bool libs::isregisteredcopied (String(id)) bool libs::isregisteredshared (String(id)) libs::unregister (String(id)) VM libs::import (String(id)) libs::unimport (VM)
Runtime compilation
bool vmcomp (String(srcPath), String(destPath), Callable onError(String errr), Bool(productionMode)) bool vmcompstring (String(code), String(destPath), Callable onError(String errr), Bool(productionMode)) bool vmcomponwriter (String(srcPath), ExternId(writer), Callable onError(String errr), Bool(productionMode)) bool vmcompstringonwriter (String(code), ExternId(writer), Callable onError(String errr), Bool(productionMode)) ExternId vmcompstringtooutputbuffer (String(code), Callable onError(String err), Bool(productionMode)) ExternId vmcomptooutputbuffer (String(srcPath), Callable onError(String err), Bool(productionMode)) String list vmextractbuilddeps (String(srcPath)) Parses depedencies ('using' #<id>) and returns: list of strings where every pair <A,B> of them explains how the deps were resolves: A is the resolved full path and B is one of: 'non_found' (then A is the unresolved file name), 'one_found' (then A is the full path) and 'many_found' (then A encompasses all viable full path separated with ;).
List and iterators
Next is garbage collectable: List list_new() list_push_back(l, x1,...,xn) list_push_front(l, x1,...,xn) Value list_pop_back(l) Value list_back(l) Value list_pop_front(l) Value list_front)l) list_insert(l, iterator i, x) Insert x before i Bool list_remove(l, x) Returns whether x was actually found and removed list_erase(l, iterator i) list_clear(l) Number list_total(l) Iter list_iterator(l) Returns a new iterator of a reset state Also, all previous functions, except list_new, may be called as methods using a list variable, without the 'list_' prefix. Next is garbage collectable: Iter listiter_new() Iter listiter_setbegin(i, l) Iter listiter_setend(i, l) Bool listiter_checkend(i, l) Bool listiter_checkbegin(i, l) Bool listiter_equal(i, j) listiter_assign(i, j) Iter listiter_copy(i) Iter listiter_fwd(i) Iter listiter_bwd(i) Number listiter_getcounter(i) Counter of current iteration element list listiter_getcontainer(i) Value listiter_getval(i) listiter_setval(i, x) Also, all previous functions, except listiter_new, may be called as methods using a list iterator variable, without the 'listiter_' prefix.
Vectors and iterators
Next is garbage collectable: Iter vectoriter_new(n) n is initial size (mandatory). Iter vectoriter_setbegin(i,v) Iter vectoriter_setend(i,v) Bool vectoriter_checkend(i,v) Bool vectoriter_checkbegin(i,v) vectoriter_equal(i,j) vectoriter_assign(i,j) Iter vectoriter_copy(i) Iter vectoriter_fwd(i) Iter vectoriter_bwd(i) Number vectoriter_getcounter(i) Counter of current iteration element vector vectoriter_getcontainer(i) Value vectoriter_getval(i) vectoriter_setval(i,x) Number vectoriter_getindex(i) Also, all previous functions, except vector_new, may be called as methods using a vector variable, without the 'vector_' prefix. Iter vectoriter_new(n) n is initial size (mandatory). vectoriter_setbegin(i,v) Bool vectoriter_setend(i,v) Bool vectoriter_checkend(i,v) Bool vectoriter_checkbegin(i,v) vectoriter_equal(i,j) vectoriter_assign(i,j) Iter vectoriter_fwd(i) Iter vectoriter_bwd(i) Value vectoriter_getval(i) vectoriter_setval(i,x) Number vectoriter_getindex(i) Also, all previous functions, except vectoriter_new, may be called as methods using a vector iterator variable, without the 'vectoriter_' prefix.
Algorithms
The following algorithms work with existing containers and iterators, but also work with user-defined containers and iterators that follow the standard library API. The container must have a method 'iterator' that returns an iterator object and the iterator must have the following methods: fwd, (equal or @operator==), setbegin, setend, getval, copy and getcontainer. To see the proper signature of the methods above, see the API of the standard library containers and iterators. In the functions below: start, end iterators cont container x any value pred callable Bool pred(Iter) func callable pred(Iter) eraser callable eraser(container, iterator) Iter find(x, start, end) Returns an iterator to the first element in the range [start,end) that compares equal to x, or end if not found. Iter find(x, cont[, end]) Same as before, except start is the first element in container cont List find_all(x, start, end) Returns a list with iterators to all the elements in the range [start,end) that compares equal to x List find_all(x, cont[, end]) Same as before, except start is the first element in container cont Iter find_if(pred, start, end) Returns an iterator to the first element in the range [start,end) for which pred is satisfied. Iter find_if(pred, cont[, end]) Same as before, except start is the first element in container cont List find_all_if(pred, start, end) Returns a list with iterators to all the elements in the range [start,end) for pred is satisfied. List find_all_if(pred, cont[, end]) Same as before, except start is the first element in container cont apply(func, start, end) Applies func to all the elements in range [start,end) apply(func, cont[, end]) Same as before, except start is the first element in container cont Iter remove(x, start, end[, eraser]) Removes from the range [start,end) the first element with a value equal to x and returns an iterator to the following element, or end if no element found. If an eraser passed, it is called instead of the default erase policy. Iter remove(x, cont[, end, eraser]) Same as before, except start is the first element in container cont remove_all(x, start, end[, eraser]) Removes from the range [start,end) all the elements with a value equal to x. If an eraser passed, it is called instead of the default erase policy. remove_all(x, cont[, end, eraser]) Same as before, except start is the first element in container cont Iter remove_if(pred, start, end[, eraser]) Removes from the range [start,end) the first element for which pred is statisfied and returns an iterator to the following element, or end if no element found. If an eraser passed, it is called instead of the default erase policy. Iter remove_if(pred, cont[, end, eraser]) Same as before, except start is the first element in container cont remove_all_if(pred, start, end[, eraser]) Removes from the range [start,end) all the elements for which pred is statisfied. If an eraser passed, it is used to remove the element. remove_all_if(pred, cont[, end, eraser]) Same as before, except start is the first element in container cont
Ast and visitors
Next is garbage collectable: Ast ast_new(tag[, attributes]) String ast_get_tag(a) Ast ast_get_child(a, index) Object ast_get_child_index(a, node) List ast_get_children(a) Number ast_get_total_children(a) Ast ast_get_parent(a) Bool ast_is_descendant(a, node) ast_push_back(a, node[, id]) ast_push_front(a, node[, id]) ast_insert_after(a, after, node[, id]) ast_insert_before(a, before, node[, id]) ast_pop_back(a) ast_pop_front(a) ast_remove(a, index / node) ast_remove_from_parent(a) ast_replace(a, old, new) Value ast_get_attribute(a, id) Bool ast_set_attribute(a, id, val) Object ast_get_attributes(a) Bool ast_accept_postorder(a, visitor) Bool ast_accept_preorder(a, visitor) Ast ast_copy(a) String ast_unparse(a) Generates a string representation of the given ast value Ast ast_escape(a, val) Inserts the given value at the next espace of the given ast. Returns the new ast (it may change). Used mainly for the code generation of the escapes (...). ast_decr_esc_cardinalities(a) Decreases the cardinality (delay factor) of all escapes of the given ast by 1. Typically follows a series of ast_escape calls. Used mainly for the code generation of quasi-quotes (...). Also, all previous functions, except ast_new, may be called as methods using an ast variable, without the 'ast_' prefix. Next is garbage collectable: AstVisitor astvisitor_new() astvisitor_set_handler(v, tag, callable) Set traversal handler for a given ast tag. astvisitor_set_context_handler(v, parentTag, childId, callable) Set a context-dependent traversal handler: for a specific parent tag, the target child. astvisitor_set_default_handler(v, callable) Set traversal handler for all nodes (fallback). astvisitor_stop(v) Terminate ast traversal. astvisitor_leave(v) On enter skips children; on exit skips siblings Also, all previous functions, except astvisitor_new, may be called as methods using an ast visitor variable, without the 'astvisitor_' prefix.